PeakLab v2 Documentation Contents R2N Software Home R2N Software Support
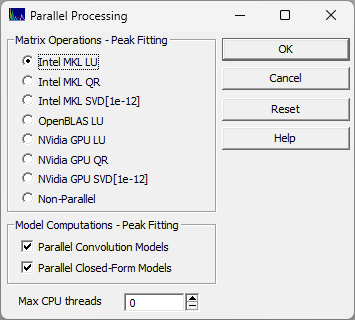
Parallel Processing
The Parallel Processing option in the Edit menu is used to specify the multithreading behavior of the program's matrix inversions, its Fourier convolutions for IRFs, and for the computationally intensive closed-form model computation. The option is also used to specify the maximum number of CPU threads that can be allocated for PeakLab parallel processing operations.
Matrix Operations
If you are fitting a large number of peaks, the inverse that is computed on each iteration can be done far more swift if parallelization is used. You will likely deem this essential for any fitting problem that involves a 500x500 matrix or larger. The following options are available:
Intel MKL LU
This is the default. It uses the Intel Math Kernel Library LU parallelization. The LU algorithm is especially well fitted to parallelization. PeakLab supplies the necessary Intel MKL DLLs.
Intel MKL QR
This also uses the Intel Math Kernel Library, but with the QR matrix algorithm. The QR algorithm is slower but offers a higher stability than the LU. PeakLab supplies the necessary Intel MKL DLLs.
Intel MKL SVD (1e-12)
This also uses the Intel Math Kernel Library SVD (Singular Value Decomposition) with a singular value threshold of 1e-12. The SVD is a very slow, computationally intense algorithm. The SVD performs a principal component noise filtration as part of the matrix computations. PeakLab supplies the necessary Intel MKL DLLs.
OpenBLAS LU
This is an alternative to the Intel Math Kernel Library LU parallelization. It uses the OpenBLAS LU parallelization algorithm. In certain instances, it may be slightly faster than the Intel library. PeakLab supplies the necessary OpenBLAS DLLs.
NVidia GPU LU
If you have a high powered NVidia GPU card, you may find a performance benefit using this LU option. You will need to install the NVidia GPU toolkit.
NVidia GPU QR
If you have a high powered NVidia GPU card, you may find a performance benefit using this QR option. You will need to install the NVidia GPU toolkit.
NVidia GPU SVD (1e-12)
If you have a high powered NVidia GPU card, this open offer the NVidia SVD (Singular Value Decomposition), again with a singular value threshold of 1e-12. Even with massive parallelization, the SVD is a slow, computationally intense algorithm. The SVD performs a principal component noise filtration as part of the matrix computations. You will need to install the NVidia GPU toolkit.
Non-Parallel
This is the single threaded option (no parallelization). It uses the Gauss-Jordan method for the inverse.
Model Computations
Parallel Convolution Models
The Fourier convolution of a peak model and an IRF is a computationally expensive procedure that must be performed on each iteration in a peak fit when an IRF model is being fitted. When this parallelization option is selected each peak in a given fit has its convolution computed on separate thread. PeakLab allows each peak to have its own specific IRF, so the convolutions are made on a per-peak basis instead of the overall data set.
Parallel Closed-Form Models
Certain closed-form model computations, such as the Gen2HVL, may benefit from parallelization.
In all cases, multiple data sets will be processed on independent threads. That is to say, all fits
will be run simultaneously. For computationally fast functions or when many data sets being fit at the
same, the benefit of this parallelizations may be nil or result in higher processing times. It is recommended
that this parallelization be turned off if you will routinely be simultaneously fitting multiple data
sets of it you are fitting simple closed form functions. The context switching overhead of the threading
may be more expensive than what is gained from the parallel processing.
Max CPU Threads
By default the parallelization in PeakLab will use all available threads. Use this option to reserve some
number of CPU threads for other processes. Under certain conditions, you may find the same performance
from eight threads, for example. as you might see from using all of the threads on your machine. Context
switching can be expensive and contention between threads can limit the performance benefit. You can assume
the threads that manage multiple data sets are global and within them are successively the threads for
the model computations and then the threads for the matrix inverse. The model computations and matrix
inverse do not run simultaneously within a given fit.