PeakLab v2 Documentation Contents R2N Software Home R2N Software Support
Peak Fit Preferences
![]() These preferences, available from PeakLab's fitting
options, control adjustable elements within PeakLab's non-linear fitting engine. Some of these options,
such as the Robust Minimization and Built-In Peak Fn Constraints can dramatically affect the fit results.
Others such as Fit Extent and the Curvature Matrix options can significantly affect the time required
for fitting large data sets when many peaks are being fitted.
These preferences, available from PeakLab's fitting
options, control adjustable elements within PeakLab's non-linear fitting engine. Some of these options,
such as the Robust Minimization and Built-In Peak Fn Constraints can dramatically affect the fit results.
Others such as Fit Extent and the Curvature Matrix options can significantly affect the time required
for fitting large data sets when many peaks are being fitted.
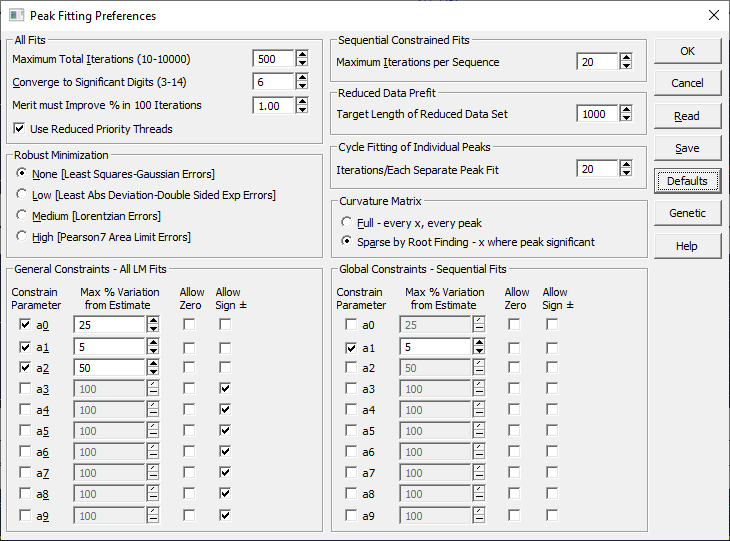
All Fits
Maximum Iterations
The default number of iterations is 500. You may enter any value between 10 and 10000. There is usually very little to gain beyond 1000 iterations. In complex strategies where dozens or even hundred of fits occur, this value will generally apply to the main step where all of the data is being used in the fitting and none of the parameters are temporarily locked.
Converge to Significant Digits(3-14)
The default non-linear convergence precision is 6. This means that the chi-square (goodness of fit) must be unchanging in the sixth decimal place for five consecutive iterations to signal convergence. You may enter any value between 3 and 14. Note that often only a few additional iterations are needed to converge to a high precision. A convergence precision of 12 may thus require very little additional fitting time than the default of 6.
Merit must Improve % in 100 Iterations
This avoids those exceptionally narrow valleys in n-dimensional space. The default is 1%. If one hundred iterations pass without at least a 1% improvement in the merit function of the fit, the convergence is signaled.
Use Reduced Priority Threads
Leave this box checked to have all fits occur on low priority threads that will allow you to work in other apps while a lengthy fit is underway. You should not need to uncheck this unless another impolite app is starving low priority threads for execution time.
Robust Minimization
In addition to standard least-squares minimization, PeakLab's Levenburg-Marquardt (LM) non-linear fitting engine is capable of three different Robust Estimations. These minimizations are sometimes referred to as maximum likelihood or m-estimate fitting.
If your data spans a large number of orders of magnitude in the Y variable and the low-valued Y points are not factoring into the fit, there are very good solutions in the PeakLab fit strategies that manage low area components with a least-squares minimization. A robust fit is an alternative to remedy this problem. This statistical fallback where data is weighted to better accommodate the low-valued Y points should not be necessary.
The instance where robust fitting is still recommended is when it is known that there are significant outliers within the data. Robust estimation will minimize the impact of outliers. This may be important when relatively few points define an individual peak.
Least-squares corresponds to a Gaussian maximum likelihood distribution of errors. All of the robust minimizations correspond with maximum likelihood probability distributions significantly less compact than the Gaussian. These wider tails mean that the errors associated with outliers are expected. When outliers are suspected or likely, the Lorentzian minimization is highly recommended. Although the same non-linear fitting engine is used for all of these minimizations, you will generally find that a higher number of iterations will be required for a robust fit as compared to least squares.
Sequential Constrained Fits
The Maximums Iterations per Sequence is used to set the count of iterations before the general constraints are used to reset the bounds or actual constraints on the parameter values. The default value is 20. Every 20 iterations in a sequential fit, the percentages specified in the general constraints are used with the current parameter values to determine new allowable bounds for the parameters.
The global constraints only apply to sequential fits, since the general constraints are themselves global if there is no sequential constraint fit, and thus no reset of these bounds, taking place. Global constraints are absolute and are never reset. The only default global constraint is a 5% variation on the placed a1 center parameter value.
Reduced Data Prefit
The Target Length of Reduced Data Set is used to determine the degree of reduction occurring in the data density for reduced data prefits. The default is 1000 points. You should be cautious of dropping this to too low a value. You will need to have enough points in each peak to qualify the higher moments. This value may need to be increased if you have large data sets with very narrow peaks.
Cycle Fitting of Individual Peaks
The Iterations/Each Separate Peak Fit specifies the count of iterations used in the focused fitting of specific peaks in the cycle peaks strategies. The default is 20 iterations.
Curvature Matrix
This is preference useful for minimizing wasted time in fitting. When constructing the curvature matrix, the partial derivatives appearing in each matrix element need not be summed for all x values in the data. Rather, a sparse procedure can be used where each element is updated only when a peak is close enough to that x value to affect the overall model.
Full - every x every peak
The Full option makes no use of sparse matrix processing. The curvature matrix is built by full evaluations at each x value for every element in the matrix.
Sparse by Root Finding - x where peak significant
The Sparse by Root Finding procedure does not suffer this limitation. At each iteration, each peak's significance limits are determined by a root finding procedure.
When fitting only a few peaks, sparse curvature matrix processing offers little to no benefit. Even with a large number of peaks, the benefit may be modest with peaks whose partial derivatives are computed very rapidly, such as Gaussians. On the other hand, the processing can yield up to tenfold reduction in fitting time for fitting large numbers of complex peaks whose partial derivative computations are particularly demanding. Do not use the sparse procedure with user defined models which do not decay from an apex to a baseline. A first or second derivative of a peak, for example, would requite the Full option.
General Constraints - All LM Fits
PeakLab's autoplacement algorithms go to great lengths to place peaks as accurately as possible. This makes it possible to impose constraints on the principal parameter values based on the original estimates. The constraints are specified as percents on the parameters. Any active constraint will apply to all built-in peak functions, regardless of model. Supplemental functions and user function are not included (user functions have their own separate constraints when they are built).
The general constraints apply to all Levenburg-Marquardt nonlinear fits. These will be global constraints for fits where the sequential constraints are not specified.
Check the a0 to a9 box in the Constrain Parameter column to constrain that parameter of a model. In general, the a0 to a3 built in models will address the zeroth to third moments and the defaults constraints are set based on that assumption.
Enter the desired constraint percentage in the Max % Variation from Estimate fields. By default the a0 area parameter is set at 25%, the a1 center parameter at 5%, and the a2 width at 50%. The other parameters are not constrained by default.
The Allow Zero box must be checked to allow a parameter to assume a 0 value, and the Allow Sign � must be checked to allow a parameter to change sign. Be especially careful of disabling the a3 allowance for chromatographic peaks. Removing this a3 sign permission will force a peak to remain intrinsically fronted or tailed as originally placed. A chromatographic peak which appears tailed as a consequence of an IRF, may actually be fronted with respect to its a3 internal chromatographic distortion.
Local minima in multidimensional non-linear fitting refers to a limitation in iterative minimization algorithms. Unlike linear least-squares, where a global minimum always occurs (and within a single step), achieving a global minimum (the optimum fit) in iterative non-linear fitting is not assured. Indeed peaks are amongst the worst of culprits for functions producing local minima. When a peak's center shifts right to where the left side of the peak function rests on the right hand decay of the peak data, a local minima condition develops. It is therefore especially important that center values be constrained and not be permitted unlimited freedom of movement.
PeakLab's fitting algorithms are designed to deal with minimization of constraint violations as well as a goodness of fit minimization. In particularly difficult fits, you may see a large number of constraints violated on initial iterations. In time the algorithm should work itself to a position in multidimensional parameter space where no constraints are violated. In conditions where constraints are readily violated, the fit algorithm may spend more iterations working itself free of constraint violations than in resolving the optimum fit parameters.
Although you may disable constraints by unchecking them, in normal practice it is recommended that you keep the a1 constraint active, and set it at a percent that prevents small peaks from wandering into the regions of adjacent ones, and that you preserve the a0 constraint, at least sufficiently to ensure that areas retain their sign. To preserve sign, a constraint must be less than 100%.
In fitting large numbers of peaks, we have found repeated instances where a given iteration shows an overall improvement in the goodness of fit merit function, but where one small amplitude peak has gone into oblivion, perhaps into a local minimum position with an adjacent peak, perhaps into a zero or negative amplitude condition, perhaps decaying to zero width, or even shifting outside the X range of the data. PeakLab's implementation of constraints are a byproduct of our experience in seeking to introduce a greater stability into the peak fitting algorithm.
Global Constraints - Sequential Fits
In sequential fits, the actual values of the bounds on the parameters are recomputed at a specified count of iterations specified in these preferences. In order to allow for absolute constraints on sequential fits, those which are never updated at any iteration, and where these bounds are set from the start of the fit, you can use these global constraints. These are identical to the general constraints except for this lack of update. By default, only the a1 center value is specified, at a 5% level.
Saving and Reading Fit Preferences
Use the Save item to save the current preferences to disk. The default file extension is [PRF]. These are binary files that can only be produced within the program. The current preferences are always saved automatically across sessions. You will want to save preferences to disk if you plan to regularly use more than one fit configuration in your work. Preference files can be recalled at anytime using the Read item.
Defaults
The Defaults button restores the PeakLab default preferences.
Genetic Algorithm Preferences
The Genetic button opens a separate dialog for the generic algorithm preferences available for the Refine Estimates with Genetic Algorithm right-click option in the placement screens.
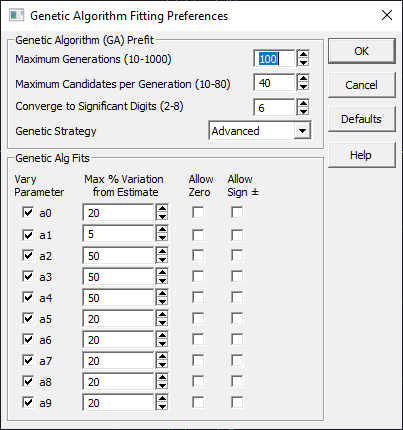
The GA (genetic algorithm) preferences dialog allows you to set the Maximum Generations, the Maximum Candidates per Generation, the Converge to Significant Digits, and a Genetic Strategy. The defaults are 100 generations, 40 candidates per generation, 6 significant digits convergence, and the Advanced algorithm. The genetic algorithm should be considered experimental, and is furnished as an alternative for difficult to place functions and for escaping settings which contain a local minimum state. The algorithm mostly determines the pace of convergence. The constraints are far more important with respect to realizing the global minimum.
The generic algorithm constraints are identical to the global LM algorithm constraints as there is no update. Unlike the LM algorithm, however, constraints are essential on all of the parameters. You will need to set these carefully. The defaults consist of small values specific to a refinement to take you out of a local minima position from a fit, not to find estimates when you have no idea of what the starting parameter values should be. The GA algorithm can be very effective in the latter, but with peak models you will need to constrain the estimates to some measure.