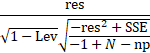
PeakLab v2 Documentation Contents R2N Software Home R2N Software Support
GLM Data
The Data button in the GLM Review opens a window containing the sample by sample error information for the fit of the model currently selected. This will be an RTF (rich text format) window where individual content can be highlighted and copied, provided the data size is less than 2048. For larger sets, a much faster display procedure is used for accommodating the display of up to the program's N=50,000 built-in data limit.
This summary is automatically updated each time a different model is selected in the Model List.
The purpose of the Data procedure is mainly to spot outliers in the modeling.
Rank 1 GLM6(1660,1670,1675,1740,1785,1840)
Data Yobserved Yestimated Residual ResStnd Student Leverage CookDist Mahalnbis SEconf SEpred AvPrResAll6 *
1 7.3115080 7.0126152 0.2988928 0.4616287 0.4637590 0.0118199 0.0003685 1.5966519 0.0703931 0.6512899 0.3588386
2 7.1901862 7.3304263 -0.140240 -0.216596 -0.218341 0.0191129 0.0001331 2.1765082 0.0895129 0.6536328 -0.084155
3 3.4974234 3.2923609 0.2050625 0.3167113 0.3179535 0.0108357 0.0001587 1.5013447 0.0673987 0.6509730 0.4253681
4 3.8522567 3.6781666 0.1740901 0.2688755 0.2712196 0.0203122 0.0002186 2.2576499 0.0922786 0.6540173 0.5084710
5 3.7504296 3.5916479 0.1587817 0.2452324 0.2463867 0.0125153 0.0001103 1.6607005 0.0724343 0.6515137 0.5516906
6 3.6791948 3.6467939 0.0324010 0.0500421 0.0502629 0.0121285 4.446e-06 1.6253851 0.0713061 0.6513892 -0.050466
7 3.6279980 3.2996027 0.3283954 0.5071942 0.5097246 0.0124072 0.0004675 1.6509071 0.0721208 0.6514789 0.4781692
8 3.5447280 3.7352658 -0.190538 -0.294278 -0.296477 0.0178377 0.0002288 2.0867773 0.0864754 0.6532238 0.3612259
9 4.0161117 4.1390045 -0.122893 -0.189803 -0.190986 0.0155879 8.278e-05 1.9182494 0.0808381 0.6525014 -0.748251
10 4.3765097 4.3228387 0.0536710 0.0828928 0.0838334 0.0256176 2.649e-05 2.5862305 0.1036314 0.6557155 -0.051032
60 4.8311070 4.5998355 0.2312715 0.3571901 0.3605942 0.0217042 0.0004133 2.3483160 0.0953882 0.6544633 0.7367690
61 4.8311070 4.1074819 0.7236251 1.1176117 1.1270856 0.0159042 0.0029304 1.9428269 0.0816542 0.6526030 0.9263489
62 1.8925833 3.2623550 -1.369772 -2.115561 -2.152663 0.0225795 0.0151114 2.4035765 0.0972927 0.6547436 -1.524194
63 1.8925833 2.5885887 -0.696005 -1.074954 -1.082207 0.0128360 0.0021744 1.6894139 0.0733563 0.6516168 -0.826546
64 1.8925833 2.0258312 -0.133248 -0.205796 -0.206342 0.0085190 5.243e-05 1.2486094 0.0597609 0.6502266 -0.376182
65 6.1752371 7.8890896 -1.713852 -2.646980 -2.729528 0.0398877 0.0433110 3.3120425 0.1293130 0.6602614 -2.481260 *
66 6.1752371 8.3443651 -2.169128 -3.350136 -3.475384 0.0371837 0.0643121 3.1872294 0.1248530 0.6594025 -2.755218 *
67 6.1752371 7.9157604 -1.740523 -2.688172 -2.766853 0.0355712 0.0394798 3.1104174 0.1221159 0.6588897 -2.402705 *
68 3.1179101 3.7438086 -0.625899 -0.966677 -0.972701 0.0125698 0.0017210 1.6656149 0.0725918 0.6515312 -0.801359
69 3.1179101 3.5004966 -0.382587 -0.590890 -0.593796 0.0119561 0.0006109 1.6093996 0.0707976 0.6513337 -0.306374
70 3.1179101 2.8411174 0.2767926 0.4274957 0.4285632 0.0077429 0.0002053 1.1516002 0.0569736 0.6499764 0.1450392
Content
Each data set is listed in a row of information. The Data set number, the observed and estimated Y or dependent variable values, and the values of the Residuals (Yobserved-Yestimated) are always shown. The remaining items are optional and selected from the Content Menu.
Standardized Residuals
The ResStnd column contains the value of the residuals divided by the standard error of the fit. This standardization uses the SE from the design fit. A given data set's data, the Y-dependent variable, or the X-independent predictors, or both, are often deemed outliers when the standardized residual's magnitude is greater than 3 standard errors. When errors are normally distributed, this detects data that is outside a 99% area of the density. For a more stringent detection, you can elect to set the criterion to +/- 2SE. Again, for normally distributed residuals, this will detect as outliers all data outside approximately a 95% area of the density.
Checking Highlight Standardized Residuals Outliers in the Outliers menu will highlight the outlier in bold:
58 13.010000 9.8452913 3.1647087 3.8120633 3.9106703 0.0271752 0.0320982 3.8949871 0.1368548 0.8413872 3.5355034
Checking Flag Standardized Residuals Outliers in the Outliers menu will gray out the outlier and bold the field that triggered the detection:
58 13.010000 9.8452913 3.1647087 3.8120633 3.9106703 0.0271752 0.0320982 3.8949871 0.1368548 0.8413872 3.5355034 *
The highlight is only a notification. The flag is an action item for the File menu's Save Data w/Flagged Outliers Removed option. This option saves the data absent the outliers for a subsequent fit.
For all options except the Prediction Interval detection, the Outlier Multiples of SE Outlier menu item is used to select Outside of 2 SE, Outside of 3 SE, or Outside of 4 SE.
Studentized Residuals
The Student column contains the Studentized residuals, an additional normalization of the errors which accounts the leverage:
where res is the residual, Lev is the leverage, SSE is the sum of the squared residuals, N is the data size, and np is the parameter count.
For this option, you check Highlight Studentized Residuals Outliers or Flag Studentized Residuals Outliers in the Outliers menu.
Because the Studentized residuals include the leverage, they will always be of a greater magnitude than the simple SE standardized residuals.
Leverage
The leverages are estimated using the diagonals of the hat matrix. The leverages are shown in a different color. This is done for influence items. A high leverage point, meaning it has a high influence in the fit, does not mean that it is an outlier. This higher influence can arise from a zone of the Y-variable which has very little representation in the data. In such an instance, the data in such a zone will have a strong influence because it is only data covering this region of the dependent variable. Removing such data and labeling it an outlier may be the last thing you want to do. You can see points with a high leverage as being possibly indicative of a Y-region that should be more thoroughly mapped, if possible, in the data matrix.
For this option, you check Highlight Leverage Outliers or Flag Leverage Outliers in the Outliers menu. You will probably only want to highlight the high leverage data as opposed to flagging such for removal.
Cook's Distance
This is also an estimate of influence, but it also takes into account the magnitude of the residual. The higher the leverage and residual, the higher the Cook�s distance:
![]()
where res is the residual, Lev is the leverage, SE is the standard error, and np is the parameter count.
For this option, you check Highlight Cook's Distance Outliers or Flag Cook's Distance Outliers in the Outliers menu.
Mahalonobis Distance
The Mahalonobis distance is another influence metric used for the detection of multivariate outliers. It can also be computed from the hat matrix leverages:
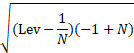
where Lev is the leverage and N is the data size.
For this option, you check Highlight Mahalonobis Distance Outliers or Flag Mahalonobis Distance Outliers in the Outliers menu.
SE Confidence Interval
The estimate of confidence interval for a given observation is:

where SSE is the sum of squared residuals, Lev is the leverage, and DOF is the degrees of freedom. This is a display only item.
SE Prediction Interval
The estimate of prediction interval for a given observation is:

where SSE is the sum of squared residuals, Lev is the leverage, and DOF is the degrees of freedom. This method is the default outlier detection method.
For this option, you use Highlight Outside Prediction Interval or Flag Outside Prediction Interval in the Outliers menu.
Unlike all of the other detection methods, here you must use the Prediction Interval Confidence item in the Outliers menu, to select 95 Confidence, 99 Confidence, or 99.9 Confidence.
Average Predicted Residuals All Models of Specific Predictor Count
The last item which can be optionally displayed is the average predicted residuals for all saved models of the size of the currently selected model. If the current model has 8 predictors, the label will read AvPrResAll8. This is especially useful for seeing if the best models of this parameter length consistently see a given data observation as an outlier. If the program's default is used and there are 100 models saved for each predictor length in the full permutation fits, there will be 100 sets of residuals which will be averaged to produce this specific column.
Data Yobserved Yestimated Residual ResStnd Student Leverage CookDist Mahalnbis SEconf SEpred AvPrResAll8 *
48 3.9700000 3.5924252 0.3775748 0.4548093 0.4585705 0.0176754 0.0002915 3.0852135 0.1103718 0.8374874 0.4040256
49 3.9700000 3.7938122 0.1761878 0.2122278 0.2141235 0.0192375 6.929e-05 3.2323363 0.1151458 0.8381299 0.3641568
50 3.9700000 2.8747623 1.0952377 1.3192732 1.3303212 0.0152877 0.0021108 2.8456765 0.1026467 0.8365043 0.8275808
51 2.8500000 2.8339846 0.0160154 0.0192914 0.0193973 0.0125776 3.693e-07 2.5466395 0.0931050 0.8353872 0.4420697
52 2.8500000 2.6842926 0.1657074 0.1996036 0.2010214 0.0156801 4.96e-05 2.8864018 0.1039555 0.8366660 -0.100701
53 2.8500000 2.6666236 0.1833764 0.2208869 0.2216625 0.0086065 3.286e-05 2.0304004 0.0770169 0.8337474 0.3767103
54 2.8500000 2.4938707 0.3561293 0.4289771 0.4329328 0.0195651 0.0002881 3.2623499 0.1161221 0.8382646 0.1148067
55 2.8500000 3.1085358 -0.258536 -0.311420 -0.313733 0.0162113 0.0001250 2.9406505 0.1057020 0.8368847 -0.153653
56 13.010000 9.3480457 3.6619543 4.4110226 4.5344158 0.0226910 0.0355570 3.5359308 0.1250548 0.8395486 3.8334506 *
Unlike all other metrics in this procedure, this item addresses the average errors in the predictions, as opposed to specific errors in the design fit.
These average errors will be the leave one out or random sampling errors for each of these data observations, averaged across all of the saved models of a specific parameter count. The values are not normalized, and are thus directly comparable with the scale of the residuals. This is an average of the errors of all retained models of this specific parameter count from the full permutation modeling. Because it is an average, a positive residual from one model, and a negative from another, will offset. If the average predicted error across all models is very close to a large residual in the current model, then you can safely assume all (or most) retained models of this parameter count fail to accurately predict this particular data set, and further, they do so about equally.
The purpose of offering this unusual addition to the outlier detection is to highlight data sets which consistently perform poorly across all models with respect to prediction error. In the above extract, data set 56 has an observed value of 13.01 and an estimated value of 9.35, a residual of 3.66. Here we address one data set, one spectrum and one Y-value that is mapped to that spectrum, and just one specific model. There is the obvious question as to what other models of this same size look like with this particular spectrum and reference value. Rather than having to step through a large number of models to answer this question, this average predicted column furnishes an immediate answer. In this instance, the high residual is not an anomaly associated with a specific model. The average predicted error for this data is 3.83 across all one hundred of the retained 8-parameter full permutation models.
This option allows you to immediately rule out, or possibly rule in, a specific model anomaly as the source of the discrepancy. As an example, let us instead say the average predicted value is much lower on this data set. There may be a wavelength or wavelength band in the model that performs poorly, and it may be missing from the models that perform with a much better accuracy.
File Menu
The Save Summary As... option will save the information in the GLM Data-Residuals Summary to a comma separated value CSV file, a tab-separated PRN file, or a space-formatted TXT file. In addition to these three ASCII formats, you can also save the file as a rich text format RTF file that preserves all formatting and can be imported into programs such as MS Word.
The Save Summary and X-Data As... option will save the information in the GLM Data-Residuals Summary as well as the raw Y and X-data to a comma separated value CSV file. This option extracts only the specific X-predictors used in the current model and writes an Excel importable file with the parameters and a text string containing the formula for the model in a cell to the far right of the sheet. It will look something like $AA$1+SUMPRODUCT($O2:$Y2,$AB$1:$AL$1). You will need to enter this cell and place an = sign at the start to make it a formula. You can then copy this formula to all of the rows, evaluating all of the design data.
The Stream Summary to MS Word or RTF file... option will open a stream target if one is not open, and it will stream the content of the summary into MS Word directly or into an RTF file. If you do not have MS Word on your machine, only the RTF option will be available.
The Save Data w/Flagged Outliers Removed will create a comma separated value CSV data matrix file with the currently flagged outliers removed. Use this option to create an outlier-free subset of the original data matrix for subsequent fitting.
Use the Printer Setup item to select and configure the printer you wish to use to print the summary. Use the Print item in the File menu to initiate the printing.
Edit Menu
Use the Copy option to place the summary on the clipboard. Both RTF and text formats will be copied.
Use the Copy w/Formatting option to use MS Word to place the formatted summary on the clipboard. No text format copy will exist.
The ASCII Editor option will convert the summary to ASCII text and open an editor. You can use the ASCII Editor to convert between different ASCII delimiters.
Style Menu
The Font Select item is used to set the Font that is used in the summary.
The Color item enables or disables the color formatting in the summary.
The HTML Format option may be of value in pasting portions of the summary into an HTML editor. This option replaces spaces in the text with no-break spaces.
Content Menu
The Standardized Residuals, Studentized Residuals, Leverage, Cook's Distance, Mahalonobis Distance, SE Confidence Intervals, SE Prediction Intervals, Average Residuals All Models (this Predictor Count),and Data ID select or deselect these sections of the summary.
The All Information item will display all of the content available in the summary.
Outliers Menu
As described above the Highlight Standardized Residuals Outliers, Highlight Studentized Residuals Outliers, Highlight Leverage Outliers, Highlight Cook's Distance Outliers, and Highlight Mahalonobis Distance Outliers highlight data sets where these metrics exceed the count of a specified multiple of standard deviations.
The Flag Standardized Residuals Outliers, Flag &Studentized Residuals Outliers, Flag Leverage Outliers, Flag Cook's Distance Outliers, and Flag Mahalonobis Distance Outliers, mark data sets as outliers where the File menu's Save Data w/Flagged Outliers Removed will strip these data from a new data matrix file.
Use the Outlier Multiples of SE options of Outside of 2 SE, Outside of 3 SE, and Outside of 4 SE to set the highlight or flag bounds for all outlier detection methods except that of prediction intervals.
The Highlight Outside Prediction Interval and Flag Outside Prediction Interval are used to enable and disable the Prediction Interval detection.
Use the Prediction Interval Confidence options of 95 Confidence, 99 Confidence, and 99.9 Confidence to to set the highlight or flag bounds for Prediction Interval outlier detection. Note that this option only impacts the prediction interval bound in this Data summary. The prediction intervals in the main GLM Review graph are independently set in the graph's toolbar.