PeakLab v2 Documentation Contents R2N Software Home R2N Software Support
![]() Import
Import
Use the File menu's Import Data Sets option in the main window is used to add individual data sets to the current PeakLab data file. Once the raw data files have been imported and saved in the PeakLab PFD format, you should not need to import the individual files again. You can import up to the PFD file limit of 25 data sets.
The data files must be in an ASCII, AIA net CDF, Excel, or DIF file format in order to be imported into PeakLab. For clipboard import, the clipboard data format must be similar to those used by Excel for storing blocks of numeric information.
In all import operations, an effort will be made to extract a main, X, and Y data title. You may accept or edit these data titles during the import procedure, or at any point further along using the program's Titles option.
ASCII Data Files
XY ASCII Files
PeakLab uses a general ASCII import algorithm that will directly read most ASCII files that have both X and Y values in the file. The X value must precede the Y value and there must be a delimiter between the values such as one or more spaces, a tab, a comma, a separate line, etc.. Although little used with chromatographic data, weights may follow the X and Y value by having an uppercase W preceding the weight value. Certain formats such as Chromeleon ASCII files are built-in, but most ASCII files should be automatically imported.
If you run into any difficulty with an ASCII file, you can paste the raw X,Y data into an Excel file and then do an Excel import. You can also use an ASCII editor to revise the file so that there is a main title in the first row, the X and Y titles in the next row separated by a tab, and remove all rows except the X,Y data rows. The X and Y values should be separated by a tab, comma, or one or more spaces. Please send us the ASCII file that failed the automated import.
![]() You normally use the Import from ASCII/AIA Data Files... option to import individual XY ASCII files.
You normally use the Import from ASCII/AIA Data Files... option to import individual XY ASCII files.
You can also use the Import from ASCII/AIA Data Files using Digital Filter option to import a reduced data stream, such as every other point. With this digital filter option you can also specify the point in the data where the import will begin.
Single Column ASCII Files
If the data lines within an ASCII data file contain a single floating point value, you will be offered the option of a single column import for that specific data file. You must confirm this single column format for each data set where this is detected. An initial X-value of 0 and an X-increment of 1 is used to generate the X values as the Y data are imported. If the first x value is 5.811096 and the delta x is 0.001321004, use the Transform Data option with the transform X=5.811096+0.001321004*X to reconstruct the X scale for the data.
![]() You must use the Import from ASCII/AIA Data Files... option to import individual single column
Y-variable (signal) ASCII files.
You must use the Import from ASCII/AIA Data Files... option to import individual single column
Y-variable (signal) ASCII files.
Multi-Column ASCII Files
If the data lines within an ASCII file contains more than two floating point values, you will be offered a multi-column read option. You must then select an X and Y column. Use the column number and the ASCII string information in the initial columns to determine the columns desired. A multi-column file must either be comma delimited or freeform with quoted strings.
![]() If you select multicolumn ASCII files in the Import from ASCII/AIA Data Files... option, it is
assumed you wish to extract one set of data from each of the multicolumn files selected. Here you must
use a space delimited or tab delimited format (a CSV comma separated value file cannot be imported in
this way).
If you select multicolumn ASCII files in the Import from ASCII/AIA Data Files... option, it is
assumed you wish to extract one set of data from each of the multicolumn files selected. Here you must
use a space delimited or tab delimited format (a CSV comma separated value file cannot be imported in
this way).
![]() If you select multicolumn ASCII files in the Import from an Excel or ASCII CSV File... option,
it is assumed you wish to extract one or more sets of data from the one multicolumn ASCII file you have
selected. Although a CSV file is typically used to ensure the management of empty or uneven cells in the
matrix, you can use the tab delimited format as well. The column selection process is identical to that
which is described for the Excel import described below.
If you select multicolumn ASCII files in the Import from an Excel or ASCII CSV File... option,
it is assumed you wish to extract one or more sets of data from the one multicolumn ASCII file you have
selected. Although a CSV file is typically used to ensure the management of empty or uneven cells in the
matrix, you can use the tab delimited format as well. The column selection process is identical to that
which is described for the Excel import described below.
AIA Chromatography Files
All AIA net CDF files are XY data files. Only net CDF data files which comply with the AIA Chromatography standard can be imported. The sample_name and experiment_title fields are used for the main title, the retention_unit is used for the X title, and the detector_unit is used for the Y title. If the actual_delay_time is non-zero, the chromatographic dead time transformation is offered: x=(time/actual_delay_time)-1.0. If this field is zero and there is an experimentally determined dead time for the column, the X=X/T0-1 transform should be applied, where T0 is this dead time.
![]() You would normally use the Import from ASCII/AIA Data Files... option to import AIA net CDF data
files. You can also use the Import from ASCII/AIA Data Files using Digital Filter option to import
a reduced data stream, such as every other point. With this digital filter option you can also specify
the point in the data where the import will begin.
You would normally use the Import from ASCII/AIA Data Files... option to import AIA net CDF data
files. You can also use the Import from ASCII/AIA Data Files using Digital Filter option to import
a reduced data stream, such as every other point. With this digital filter option you can also specify
the point in the data where the import will begin.
Excel Files
![]() You must use the Import from an Excel or ASCII CSV File... option to import data from an Excel
file. XLSX and the older XLS formats are supported. The initial rows of the spreadsheet are scanned for
text strings. You must have at least one cell entry, a string, in these initial rows in order for a column
to be available for selection. Use these text strings and the column designation to select an X and Y
column. You will not need the Weights
column for chromatographic data.
You must use the Import from an Excel or ASCII CSV File... option to import data from an Excel
file. XLSX and the older XLS formats are supported. The initial rows of the spreadsheet are scanned for
text strings. You must have at least one cell entry, a string, in these initial rows in order for a column
to be available for selection. Use these text strings and the column designation to select an X and Y
column. You will not need the Weights
column for chromatographic data.
The X and Y columns can come from any page or sheet within these files. The column selection list box will show both the sheet and column in an Excel-like nomenclature, ie. Sheet2!D. A valid pair of X and Y values must exist within a spreadsheet row in order for the X-Y data point to be added. For all Excel file import, an attempt will be made to read a main title from the first row of the spreadsheet file. In order to have this title available, the first row must contain only one string entry. It can be in any column.
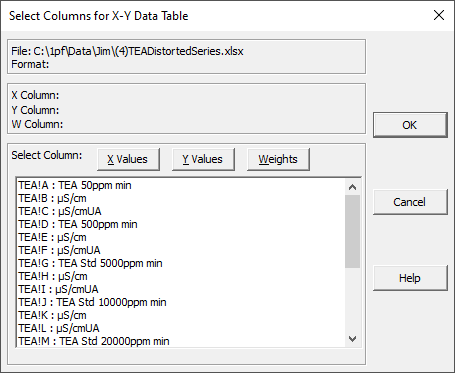
When importing data from an Excel or multicolumn ASCII file, you must select the X and Y columns for each data set. After the first XY import, the initial X selection will still be available in case there is a single X, many Y structure of data. After the second XY import with a separate X, this first X entry will disappear, and separate X columns will be assumed for each data stream. After each import you will be shown the main, X, and Y titles imported which you can either accept or revise prior to specifying the next data set in the import. Click Done when you are finished adding data sets. Otherwise, continue selecting X and Y values to up to the program's maximum of 25 data sets.
You can use the Import from an Excel or ASCII CSV File using Digital Filter import option to import a reduced data stream, such as every other point. With this digital filter option you can also specify the point in the data where the import will begin.
DIF Format Files
![]() Use the Import from an Excel or ASCII CSV File... option to select XY data from the various fields
of a DIF file.
Use the Import from an Excel or ASCII CSV File... option to select XY data from the various fields
of a DIF file.
These will be processed identically to multicolumn ASCII files.
Clipboard Data
Clipboard data can be also imported. It is also processed similarly to a multicolumn ASCII file, although there is no column selection if a clear XY format is present.
![]() Use the Import from Clipboard... option to initiate this import. The Import from Clipboard using
Digital Filter option is also available.
Use the Import from Clipboard... option to initiate this import. The Import from Clipboard using
Digital Filter option is also available.
DAD 3D Data
The Import DAD 3D Spectra... option allows multiple data sets to be imported from a DAD matrix stored as an ASCI CSV file.
Automatic UTF to ASCII File Conversion
If the imported file is a UTF-8 or UTF-16 format text file, PeakLab will automatically convert the file to a standard 8-bit ASCII numeric file with no beginning of file markers. If you have a UTF text file named SAMPLE.CSV, the file will be converted to SAMPLE(1).CSV. If the original file is a UTF-16 file, this will reduce the size of the file by half, but there will be no loss of numeric precision. In any subsequent import you should use the converted file with the (1) suffix to avoid having a new conversion occur.