PeakLab v2 Documentation Contents R2N Software Home R2N Software Support
GLM Numeric
The Numeric button in the GLM Review opens a window containing the numeric information for the fit of the model currently selected. This will always be an RTF (rich text format) window where individual content can be highlighted and copied.
This summary is automatically updated each time a different model is selected in the Model List.
Fit Statistics
Rank 64 Step6(1660,1670,1685,1750,1790,1840)
Data: 301 Observations
Fit Statistics
r2 SE F-stat AICc BIC MDL DOF
0.9592756 0.6405000 1154.2112 595.41678 624.58051 654.85546 294
The Fit Statistics section lists the raw model fit statistics. These are the non-predictive fit statistics, the goodness of fit from that which is typically known as the design or calibration fit.
For the following goodness of fit, these different items are used:
N = count of data observations
np = count of parameters (includes constant)
nx = count of x predictors (np-1)
DOF = degree of freedom, N-np
SSE = sum of squared errors from the evaluated model
SSM = sum of squares about the mean of the dependent variable
MSR = mean square regression
MSE = mean square error
Log[] = natural logarithm
r� (Coefficient of Determination)
![]()
SE (Fit Standard Error)
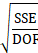
F-stat (F-statistic)
![]()
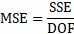
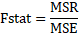
AICc (Akaike Information Criterion corrected)
![]()
BIC (Bayesian Information Criterion)
![]()
MDL (Minimum Description Length)
![]()
These statistics will reflect the least-squares minimization of errors in the fitting problem. Since these statistics do not reflect the predictive power of a model, they should be seen primarily as informational. Model decisions should not be based on these goodness of fit statistics. These are, however, the statistics you should see in cross-checking the program's fitting with a good multivariate fitting application.
Prediction Statistics
Leave One Out
Prediction Statistics - from Original Fit - Leave One Out
r2 SE F-stat AICc BIC MDL DOF
0.9571177 0.6572508 1093.6622 610.95837 640.12210 669.96597 294
Median Err Avg Err Avg Err Q1 Avg Err Q2 Avg Err Q3 Avg Err Q4 Avg Err Q5
0.3277360 0.4644907 0.4639785 0.3517798 0.4364161 0.3908856 0.6712738
Quintile Lower Upper
First 0.0600000 2.1580538
Second 2.1580538 2.9349223
Third 2.9349223 3.5834400
Fourth 3.5834400 6.1752371
Fifth 6.1752371 14.852395
The Prediction Statistics will reflect the prediction algorithm selected at the time of fitting. The default method is 'Leave One Out'. In this method, one fit is made for each data sample or set of predictors in the data, and in that fit, this specific data set is omitted from the fitting. The resultant model is then used to predict the value for the omitted data sample. In the above example, 301 spectra were fitted to a six parameter model. For this case, the 'leave one out' procedure means there will be 301 separate fits, 301 separate sets of estimated parameters, and the final statistics will be based on 301 predictions for each of the 301 data samples. Please note that none of the 301 leave one out parameter sets are stored, nor are you shown the specific goodness of fit values for any of these 301 fits.
In the prediction statistics, there is thus no least-squares minimization of all 301 of the spectra. There is only the model's design fit, and a set of 301 predictions, each based on a separate fit where that specific observation or spectra has been omitted, and the sum of squares of the error of prediction replaces the SSE in the equations above.
The prediction statistics also include the more robust average and median of the prediction errors, as well as the specific average errors in the five quintiles of the dependent variable. The quintile average errors allow you to see the specific errors in five discrete bands of the Y-variable, and by default these are shown as variations in the background color in the GLM Review graph.
Note that the GLM Model List can be sorted by any one of these prediction statistics.
As in this example, you should expect the prediction goodness of fit values to be weaker than those of the design fit. This is because the errors are based on fits which have not seen the specific data being predicted. In general, assuming the fit is deterministic, and there is very little fitting of noise in the data (overfitting), the differences in design and prediction goodness of fit will be small, especially for large N.
Random Sampling
There are two types of random sampling prediction errors. One produces averages and the other is useful for a worst-case prediction scenario.
Fit Statistics
r2 SE F-stat AICc BIC MDL DOF
0.9584280 0.6471317 1129.6771 601.61777 630.78150 660.88457 294
Prediction Statistics - from Original Fit - Random Sampling (average) 10 sets - size 100
r2 SE F-stat AICc BIC MDL DOF
0.9571765 0.6568003 1095.2304 610.54556 639.70929 669.56462 294
Median Err Avg Err Avg Err Q1 Avg Err Q2 Avg Err Q3 Avg Err Q4 Avg Err Q5
0.3431854 0.4716791 0.4527721 0.3689341 0.4733150 0.3997943 0.6562304
The default random sample test size excludes 1/3 of the data and fits 2/3 of the observations. The default of 10 sets will usually ensure that each of the spectra are predicted at least once. You will know if the sampling is complete by the DOF being equivalent between the design and prediction sections, as is the case above. If not, you may wish to increase the repetition count from 10 to 15, or perhaps even 20.
In this example, each of the ten fits processed 100 predictions, 1000 in all. Certain of these spectra are thus predicted multiple times, others just once or not at all. When multiple predictions occur, all are averaged if the average method was chosen at the time of fitting. If the worst case (minimum prediction performance) is chosen, the weakest prediction of the multiple predictions is used for the error of that sample. If you want to see a large count of predictions for each sample (the actual count for each data sample will randomly vary), you can select a much higher test count. Note that this will significantly increase the overall computation time for the fitting. The following increases the repetitions from 10 to 100:
Prediction Statistics - from Original Fit - Random Sampling (average) 100 sets - size 100
r2 SE F-stat AICc BIC MDL DOF
0.9571679 0.6568662 1095.0007 610.60600 639.76973 669.62339 294
Median Err Avg Err Avg Err Q1 Avg Err Q2 Avg Err Q3 Avg Err Q4 Avg Err Q5
0.3154644 0.4629956 0.4673276 0.3519675 0.4339845 0.3847835 0.6687526
This will increase the accuracy of the estimates of the individual prediction errors.
The real benefit of a large random sampling comes from random sets that omit many of the spectra which bound or bracket the modeling problem. To see this clearly, you will need to use the minimum prediction performance method and a larger count of test sets. This is the same random sampling with 100 sets, but where only the worst prediction for each of the spectra are used in the prediction statistics:
Prediction Statistics - from Original Fit - Random Sampling (worst) 100 sets - size 100
r2 SE F-stat AICc BIC MDL DOF
0.9134036 0.9339894 516.84342 822.50077 851.66450 875.51200 294
Median Err Avg Err Avg Err Q1 Avg Err Q2 Avg Err Q3 Avg Err Q4 Avg Err Q5
0.6503590 0.7872908 0.8164615 0.6326284 0.6824345 0.7397653 1.0554342
Note that the errors are much higher, reflecting the worst case instance where the bracketing of the fitting problem was diminished by the exclusion of the random sampling.
Parameter Statistics
The Parameter Statistics section lists the X-predictors, typically by wavelength or wavenumber, their fitted values, and the statistics for that specific predictor or X-variable. The table will display the standard error, the t-value for significance, the 95% confidence band for that parameter, and the probability of that parameter being effectively zero. You can use the Student's t tables for the t-values, but in general, you want to see magnitudes that are at least 2.0-2.5 for each of the predictors to be deemed significant. In the Options menu, you can select 90, 95, 99, 99.9, or 99.99% confidence intervals about the parameters.
Parameter Statistics
Parm Value Std Error t-value 95%ConfLo 95%ConfHi P>|t|
Constant 1.408300609 1.490640133 0.944762306 -1.52537709 4.341978310 0.34556
1660 -3879.70058 167.1072929 -23.2168239 -4208.57871 -3550.82245 0.00000
1670 2436.247498 387.6045114 6.285395104 1673.416358 3199.078638 0.00000
1675 2765.287416 288.5948170 9.581902559 2197.313858 3333.260974 0.00000
1740 -2325.26226 107.6386308 -21.6024883 -2537.10216 -2113.42237 0.00000
1785 1943.063940 102.2543997 19.00225267 1741.820564 2144.307315 0.00000
1840 -940.435580 56.70643154 -16.5842843 -1052.03756 -828.833598 0.00000
In general, the program's fitting ensures that all parameters in all models presented for selection will meet significance limits. The constant in the linear model is not tested, however, since in very good fits, this value may not be be statistically different from zero. A constant very nearly zero is not an indicator of a suspect model. That only occurs when one of the predictors or X-variables has a |t| < 2-2.5.
Analysis of Variance
The Analysis of Variance section displays a standard ANOVA table:
Analysis of Variance
Source Sum of Squares DF Mean Square F Statistic P>F
Regr 2838.3825 6 473.06376 1128.43 0.00000
Error 123.25166 294 0.41922332
Total 2961.6342 300
Fit Details
The Fit Details section displays a summary of the fitting methodology and options:
Fit Details
Full Permutation Fits Predictor Counts: 1 2 3 4 5 6 7 8
Full Permutation Fits Filters: 100 100 100 100 70 50 40 30
Stepwise Fits Max Predictor Count: 12
Stepwise Fits t to Enter: 2.5
Stepwise Fits t to Remove: 2
Process Each Predictor Count: 1000
Keep Each Predictor Count: 100
Sort By: Predicted r2
X Column Spacing: 5
Prediction Errors: Random Sampling (minimum) test size=100 repeats=100
C++ and Visual BASIC Code Generation
The Options menu will add C++ or VB code for the model currently selected.
C++ Language Code - argument is specific spectra
double glm01(double *spec)
{
// spec[0] X Predictor 1 (1660, index=110)
// spec[1] X Predictor 2 (1670, index=120)
// spec[2] X Predictor 3 (1675, index=125)
// spec[3] X Predictor 4 (1740, index=190)
// spec[4] X Predictor 5 (1785, index=235)
// spec[5] X Predictor 6 (1840, index=290)
double p[7]= {
1.40830060931456, -3879.70058429827, 2436.24749834169, 2765.28741586271, -2325.26226202815,
1943.0639397443, -940.435579831269,
};
int nx = 6;
double estimate = p[0];
for(int i=1; i<=nx; i++)
estimate += p[i]*spec[i-1];
return estimate;
}
C++ Language Code - argument is full spectra
double glm02(double *spec)
{
// X Predictor 1 (1660, index=110)
// X Predictor 2 (1670, index=120)
// X Predictor 3 (1675, index=125)
// X Predictor 4 (1740, index=190)
// X Predictor 5 (1785, index=235)
// X Predictor 6 (1840, index=290)
int idx[6]= {
110, 120, 125, 190, 235,
290,
};
double p[7]= {
1.40830060931456, -3879.70058429827, 2436.24749834169, 2765.28741586271, -2325.26226202815,
1943.0639397443, -940.435579831269,
};
int nx = 6;
double estimate = p[0];
for(int i=1; i<=nx; i++)
estimate += p[i]*spec[idx[i-1]];
return estimate;
}
There are two options for the C++ and VB generation. You can pass the individual spectra values that the model requires in the incoming spectra array, or you can pass all values in the spectrum. The only difference in the code is the bookkeeping associated with the predictors.
VBA - Excel - all spectra across columns in a single row
Function GLMEvalFull(Spectra As Range) As Double
' Spectra in Spectra.Cells(1,111) X Predictor 1 (1660, index=111)
' Spectra in Spectra.Cells(1,121) X Predictor 2 (1670, index=121)
' Spectra in Spectra.Cells(1,126) X Predictor 3 (1675, index=126)
' Spectra in Spectra.Cells(1,191) X Predictor 4 (1740, index=191)
' Spectra in Spectra.Cells(1,236) X Predictor 5 (1785, index=236)
' Spectra in Spectra.Cells(1,291) X Predictor 6 (1840, index=291)
Dim N As Integer
Dim i As Integer
Dim eval As Double
Dim parms(21) As Double
parms(1) = 1.40830060931456
parms(2) = -3879.70058429827
parms(3) = 2436.24749834169
parms(4) = 2765.28741586271
parms(5) = -2325.26226202815
parms(6) = 1943.0639397443
parms(7) = -940.435579831269
Dim idx(20) As Integer
idx(1) = 111
idx(2) = 121
idx(3) = 126
idx(4) = 191
idx(5) = 236
idx(6) = 291
eval = parms(1)
N = 6
For i = 1 To N
eval = eval + Spectra.Cells(1, idx(i)) * parms(i + 1)
Next i
GLMEvalFull = eval
End Function
The VBA code is designed to work in Excel. As written, the spectra must be placed sequentially across columns in a single row, and the cell range will span from the first to the last spectral value used in the fitting.
File Menu
The Save As... option will save the information in the GLM Numeric Summary to a comma separated value CSV file, a tab-separated PRN file, or a space-formatted TXT file. In addition to these three ASCII formats, you can also save the file as a rich text format RTF file that preserves all formatting and can be imported into programs such as MS Word.
The Stream to MS Word... option will open a stream target if one is not open, and it will stream the content of the summary into MS Word directly or into an RTF file. If you do not have MS Word on your machine, only the RTF option will be available.
Use the Printer Setup item to select and configure the printer you wish to use to print the summary. Use the Print item in the File menu to initiate the printing.
Edit Menu
Use the Copy option to place the summary on the clipboard in both RTF and text formats. If you have selected only a portion of the text, highlighting it with the mouse, only this content will be copied.
The ASCII Editor option will convert the summary to ASCII text and open an editor. You can use the ASCII Editor to convert between different ASCII delimiters.
Style Menu
The Font Select item is used to set the Font that is used in the summary.
The Color item enables or disables the color formatting in the summary.
The HTML Format option may be of value in pasting portions of the summary into an HTML editor. This option replaces spaces in the text with no-break spaces.
Options Menu
The Fit Statistics, Prediction Statistics, Parameter Statistics, Analysis of Variance, and Fit Details options select or deselect these sections of the summary.
The C++ Code - Input Specific X-Predictors, C++ Code - Input Full &X-Predictor Array, VB Code - Input Specific X-Predictors, and VB Code - Input Full &X-Predictor Array items add the C++ and VB code to the summary, as described above. Note that the Excel export options will write the formulas for the models directly in cells. Note also that the GLM Prediction option offers a copy option for predictions which supports Maple and Mathematica in addition to Excel and C++.
The Confidence menu item offers 90% Confidence, 95% Confidence, 99% Confidence, 99.9% Confidence, and 99.99% Confidence for the parameter confidence intervals. Note that this option only impacts the confidence interval of the parameters in the Numeric summary. The prediction intervals in the main GLM Review graph are set in the graph's toolbar.