PeakLab v2 Documentation Contents R2N Software Home R2N Software Support
IRF Estimation - GC
In the LC Estimation examples for the IRF, we focused upon the <ge> and <e2> IRFs, the instrument response functions containing two components, either a sum of kinetic and probabilisitic components, or a sum of two kinetic components. In GC, where it is assumed any kinetics in the chromatography would be too fast to measure, and all can be viewed as a matter of diffusion, you might expect to see very different IRFs. In our experience, the IRFs applicable to LC are also perfectly applicable to GC, even if different mechanisms must be proposed for the components of the IRF.
Fitting a GC Data IRF using the GenHVL<e> Model
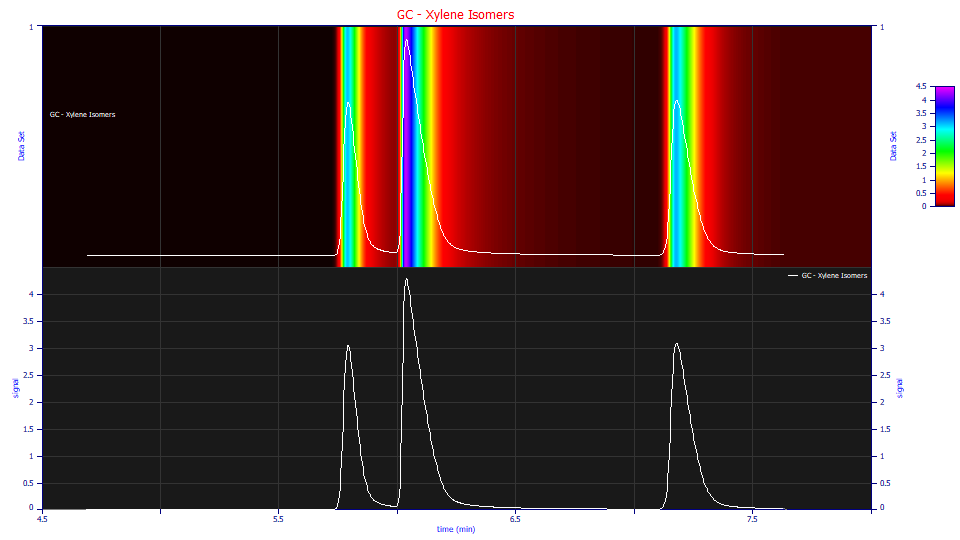
Here we will use GC data where xylene isomers are separated:
The peaks have an elongated tail which is especially apparent in the contour plot in the View and Compare Data option. Such a tail might well suggest a first order exponential IRF is all that is needed to model the decay.
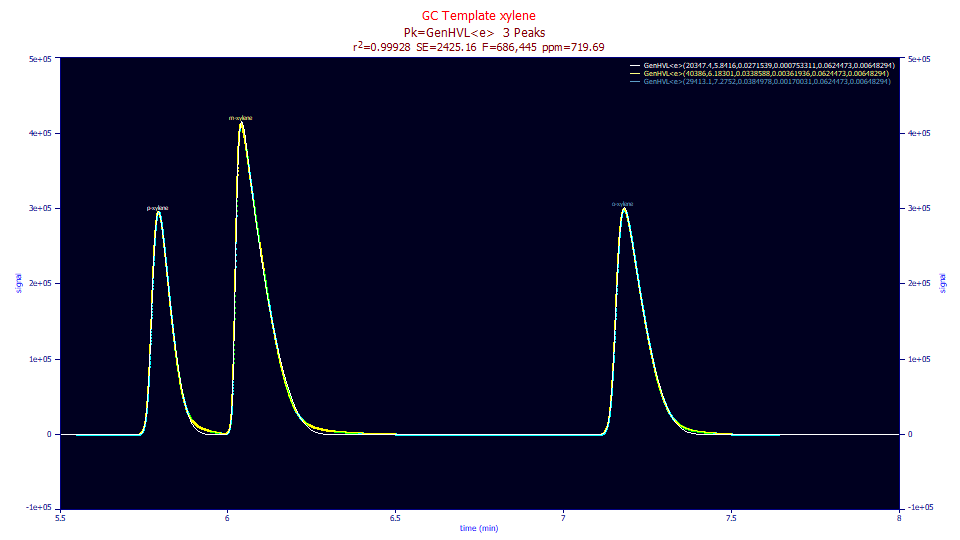
The GenHVL<e> fit to this data has a 719 ppm unaccounted variance, and as is apparent in the plot above, fails to model the instrumental tailing. Here we require the exponential time constant to be shared across all peaks, as is typically done with an IRF. When a peak looks reasonably compact in its decay until near the baseline where it explodes into a major elongation, a two-component IRF is typically needed. A simple exponential cannot convolve a peak and produce this rapidly changing shape. An IRF with both a fast and slow kinetic component, or one with a slow kinetic component and a narrow probabilisitic width, is needed.
Fitting a GC Data IRF using the GenHVL<ge> Model
If we fit the GenHVL<ge> model:
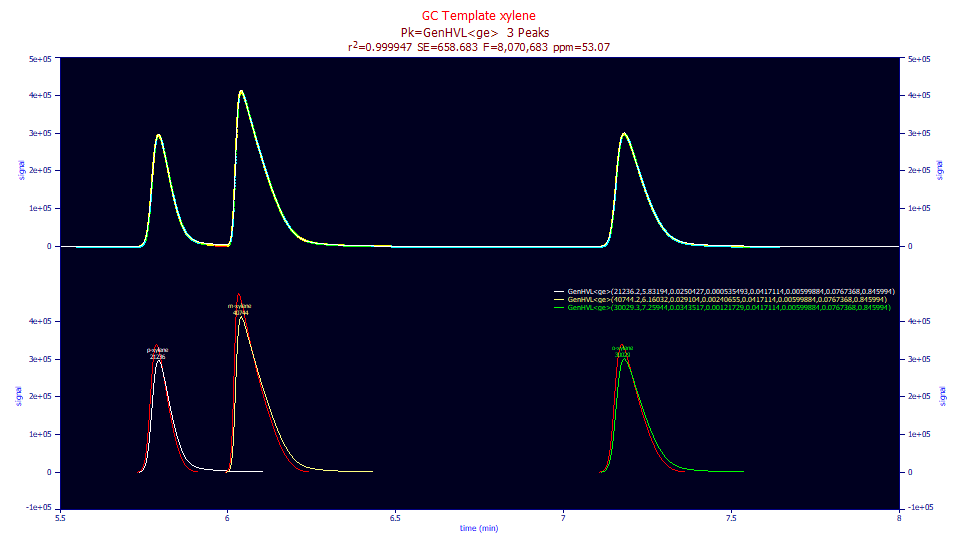
Fitted Parameters
r2 Coef Det DF Adj r2 Fit Std Err F-value ppm uVar
0.99994693 0.99994680 658.682599 8,070,683 53.0699319
Peak Type a0 a1 a2 a3 a4 a5 a6 a7
1 GenHVL<ge> 21236.2296 5.83193890 0.02504268 0.00053549 0.04171136 0.00599884 0.07673679 0.84599446
2 GenHVL<ge> 40744.2218 6.16032299 0.02910401 0.00240655 0.04171136 0.00599884 0.07673679 0.84599446
3 GenHVL<ge> 30029.3030 7.25943564 0.03435175 0.00121729 0.04171136 0.00599884 0.07673679 0.84599446
The fit is visually much improved and the 53 ppm is close to two orders of magnitude better in the unaccounted variance and all parameters test as significant. It is interesting that 85% of the IRF's area fits to this very narrow half-Gaussian. Only 15% fits to the exponential, and yet this component is responsible for the visible tailing. The IRF deconvolution is shown in the lower plot in red. The very strong tailing of the IRF is removed in this deconvolution.
Fitting a GC Data IRF using the GenHVL<e2> Model
If we fit the GenHVL<e2> model:
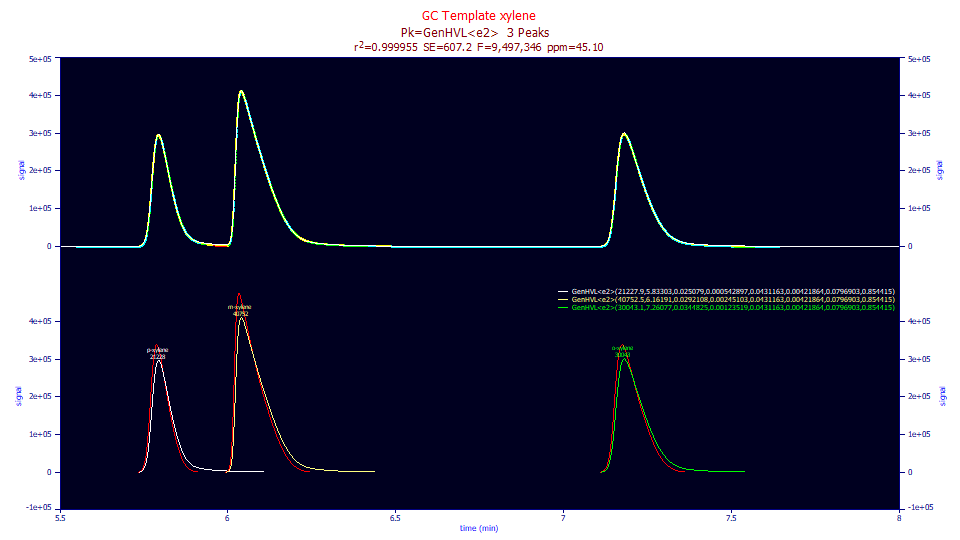
Fitted Parameters
r2 Coef Det DF Adj r2 Fit Std Err F-value ppm uVar
0.99995490 0.99995479 607.200240 9,497,346 45.0982841
Peak Type a0 a1 a2 a3 a4 a5 a6 a7
1 GenHVL<e2> 21227.9396 5.83302708 0.02507899 0.00054290 0.04311635 0.00421864 0.07969028 0.85441528
2 GenHVL<e2> 40752.4698 6.16190676 0.02921077 0.00245103 0.04311635 0.00421864 0.07969028 0.85441528
3 GenHVL<e2> 30043.1433 7.26076525 0.03448250 0.00123519 0.04311635 0.00421864 0.07969028 0.85441528
In the GenHVL<e2>, the the a6 fits to the slow (higher time constant) exponential component with almost the same value and the same area fraction as seen in the GenHVL<ge> fit. The goodness of fit is also somewhat better at 45 ppm unaccounted variance. The better fit coupled with the significance in all parameters, suggests that the <e2> model, the sum of two first-order kinetic delays, is the slightly better IRF model for this GC data set.
The fast exponential component, a5, is about 20x faster, and statistically significant even at this high kinetic rate. This fast component fits to 85% of the overall distortion, but its impact upon the observed tailed shape is small because of this very small time constant.
If the directional Gaussian or probabilistic component of the <ge> IRF mostly addresses the axial dispersion in liquid systems, then it may make sense the two component kinetic model better describes the IRF of GC systems. Here we can only suggest that the GenHVL<e2> may be the model of choice for GC data as opposed to the GenHVL<ge> model. In our development work, we did not have access to GC data with the same exceptional S/N we had in our LC data.
We note that the a4 ZDD asymmetry is high. The program's default, for LC data, is 0.016. These peaks fit to a statistical asymmetry that is almost 3x higher. The a3 chromatographic distortion is also strongly tailed, but did not fit to an increasing trend as the three peaks eluted, unlike the a2 deconvolved Gaussian width which has a clear widening. In this instance, the a3 lack of clear trend may be baseline related. Peaks can appear to be baseline-resolved, as the first two in this data, but the long sloping decay of the IRF may mean there is no decay to an actual baseline between the peaks. If one is actually assigned, errors in the a3 chromatographic shape can occur.
Despite the IRF and intrinsic chromatographic distortion both being tailed, these fits were significant in all parameters and the IRFs were successfully estimated for both models. The narrow width component is somewhat narrower than our LC examples, the wider exponential somewhat larger, and there is more of the narrow component in the overall area, but overall the IRFs are of the same general values. Consider the LC <ge> IRF of the first IRF Estimation example: [0.0080, 0.0432, 0.621]. Here we have [0.0060, 0.0767, 0.846].
We also note that the <e2> and <ge> IRFs are extremely general two-component models. One is a two-component sum of first order kinetic delays and the other a blend of first order kinetic and one-sided probabilistic delays. These are far and away the simplest IRF models that can address such shapes.
Fitting a GC Data IRF using the GenHVL<pe> Model
Although we cannot offer an explanation as to why the blend of an order 1.0 and order 1.5 kinetic decay would better fit this data (as in postulating a second order step somewhere in the broadening), we do see an improved fit with the GenHVL<pe> model incorporating this IRF:
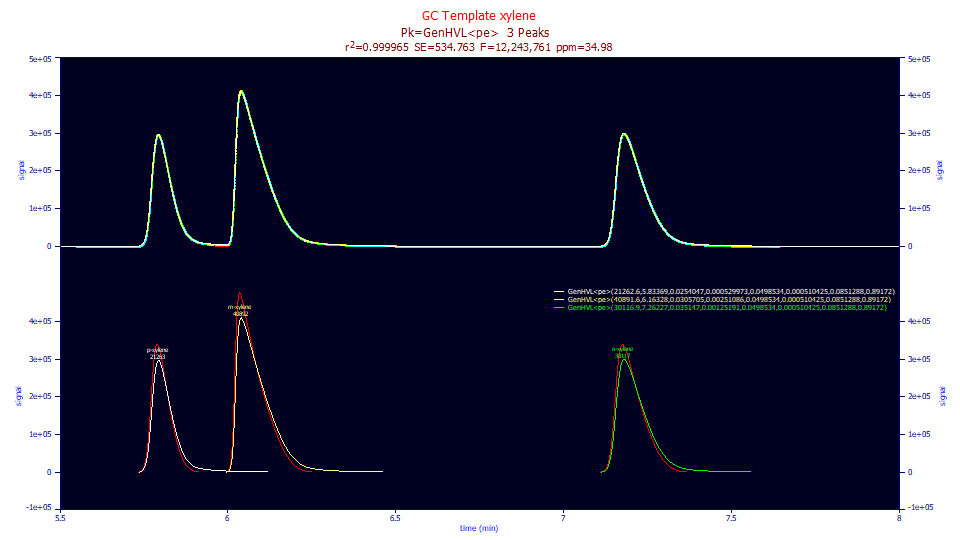
Fitted Parameters
r2 Coef Det DF Adj r2 Fit Std Err F-value ppm uVar
0.99996502 0.99996493 534.762638 12,243,761 34.9825784
Peak Type a0 a1 a2 a3 a4 a5 a6 a7
1 GenHVL<pe> 21262.5789 5.83369208 0.02540475 0.00052997 0.04985337 0.00051042 0.08512876 0.89172026
2 GenHVL<pe> 40891.5864 6.16327616 0.03057046 0.00251086 0.04985337 0.00051042 0.08512876 0.89172026
3 GenHVL<pe> 30116.9165 7.26226886 0.03514699 0.00125191 0.04985337 0.00051042 0.08512876 0.89172026
The 34 ppm unaccounted variance error is a better goodness of fit and we have an F-statistic of 12.2M as opposed to 8.1M or 9.5M. Here we see an even higher narrow component fraction, perhaps not surprising given that the <pe> IRF's 1.5 order component will have a rapid drop with long sloping tails. All of the parameters fit to significance. This example may be an anomaly, and in general the <pe> IRF is much harder to fit, at least with LC data, but its better fit with this data makes this very different IRF worthy of note.
All three of the two-component IRFs appear to be viable offering exceptional fits with this sample GC data. All produce essentially the same deconvolved a0-a3 HVL values. Even the a4 ZDD asymmetry values are respectably close, a lovely outcome given that the tailed IRF components must coexist with this ZDD asymmetry which is also tailed and which operates on the a3 primary shape which is likewise tailed.
If you find your GC data consistently fits to any one of these three two-component IRF models with 10 ppm error or less, we would greatly appreciate your sharing your experience and sample data with us.
Fitting a GC Data IRF using the GenNLC<pe> Kinetic Model
In all of the prior examples, we used the GenHVL models which fit a diffusion width. Because of how PeakLab implements the GenNLC, it is possible to fit kinetic models. We would expect the kinetic rates to be very, very fast, the time constants exceptionally small, much smaller than the sampling increment of the data:
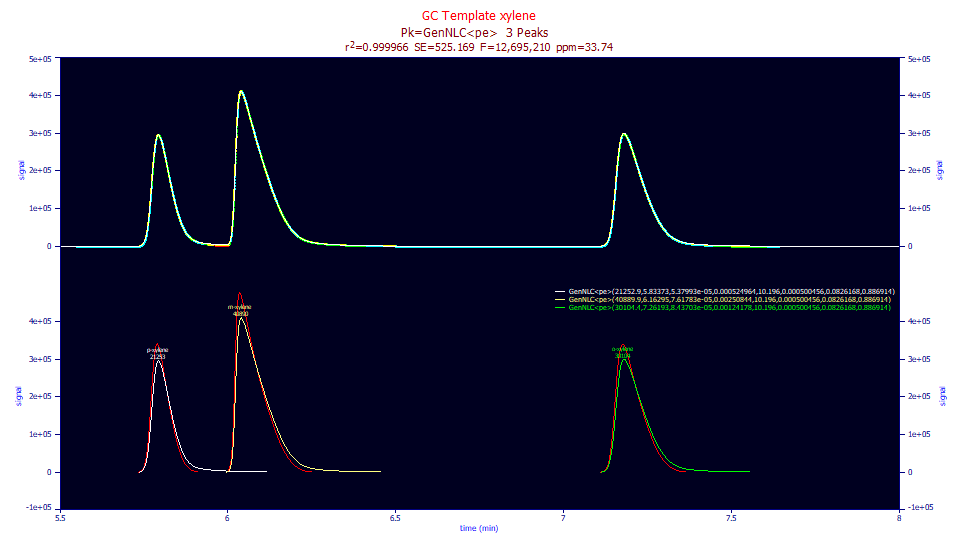
Fitted Parameters
r2 Coef Det DF Adj r2 Fit Std Err F-value ppm uVar
0.99996626 0.99996618 525.168670 12,695,210 33.7386205
Peak Type a0 a1 a2 a3 a4 a5 a6 a7
1 GenNLC<pe> 21252.8995 5.83373093 5.3799e-5 0.00052496 10.1960469 0.00050046 0.08261683 0.88691411
2 GenNLC<pe> 40889.9119 6.16294636 7.6178e-5 0.00250844 10.1960469 0.00050046 0.08261683 0.88691411
3 GenNLC<pe> 30104.3519 7.26192745 8.437e-5 0.00124178 10.1960469 0.00050046 0.08261683 0.88691411
Sharing the a4 asymmetry indexed to the Giddings density, the goodness of fit improves slightly. Here we mainly look at a2 and a4 since the other parameters are nearly identical to the GenHVL<pe> which can be deemed a diffusion or statistical peak. As a kinetic peak, we see an a2 first order time constant that increases (the rate slows) with elution location. Its value is 0.000054 to 0.000084 in retention units. As expected, this is much smaller than our sample delta-x of 0.000324. Unlike the arguments in Fourier analysis associated with sampling rate, in fitting a kinetic model we are able to estimate kinetic rates appreciably faster than our sampling.
Even more interesting, perhaps, is the a4 ZDD asymmetry which is indexed to the Giddings first order kinetics at a value of 0.5 (a pure HVL has an a4=0 just as is true with the GenHVL models). With an a4 of 10.2, we fit to an infinite dilution right-skewed asymmetry that is 20x higher than the basic Giddings first order kinetic assumption. These peaks, minus the IRF, are far, far from Gaussian.
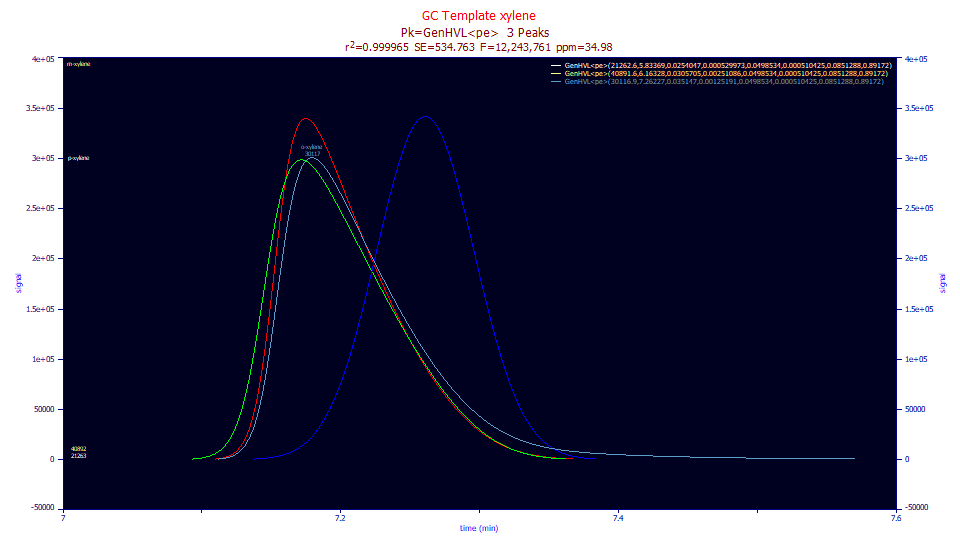
If we look at the different deconvolutions in the Review, the sky blue eluted peak becomes the red peak when the IRF is removed. The removal of the IRF results in a sharpening of the peak and the absence of the long sloping tail. When the red peak's a4 deviation from the HVL is removed, the pure HVL, the green peak, is recovered. It is also a sharply tailed shape. If the green HVL's chromatographic distortion is removed, the pure Gaussian, the bright blue peak, is recovered.
If you compare the sky blue peak as eluted with the bright blue Gaussian, this is a visual indication of just how very far these GC peaks are from Gaussian as registered by the instrument. If you compare the red peak, the eluted peak without the IRF tailing and bright blue Gaussian, the difference is similar. In this instance, the a3 chromatographic distortion is far and away the greatest factor in the non-Gaussian nature of the peak. If you look closely at the deconvolutions it is hard to estimate whether the ZDD non-ideality (represented in the shift between the red and green peaks) or the IRF (the shift between the sky blue and red peaks) is next in terms of impact; only that both are significant.
To fit GC data accurately, you will need to address the IRF, the ZDD non-ideality, and the intrinsic chromatographic distortion just as is done with isocratic LC peaks. GC peaks do not present a simpler fitting problem. In this example, the fit is more demanding: the IRF has greater tailing, the ZDD has a greater deviation from the theoretical zero-distortion shapes, and the a3 chromatographic tailing is appreciable.
Fitting GC Data using the EMG Model
This should suggest the EMG, the model traditionally used for fitting GC peaks, would have a horrible fit. The EMG is the Gauss<e> in our convolution nomenclature, a Gaussian as the core peak, and a single component first order exponential as the IRF:
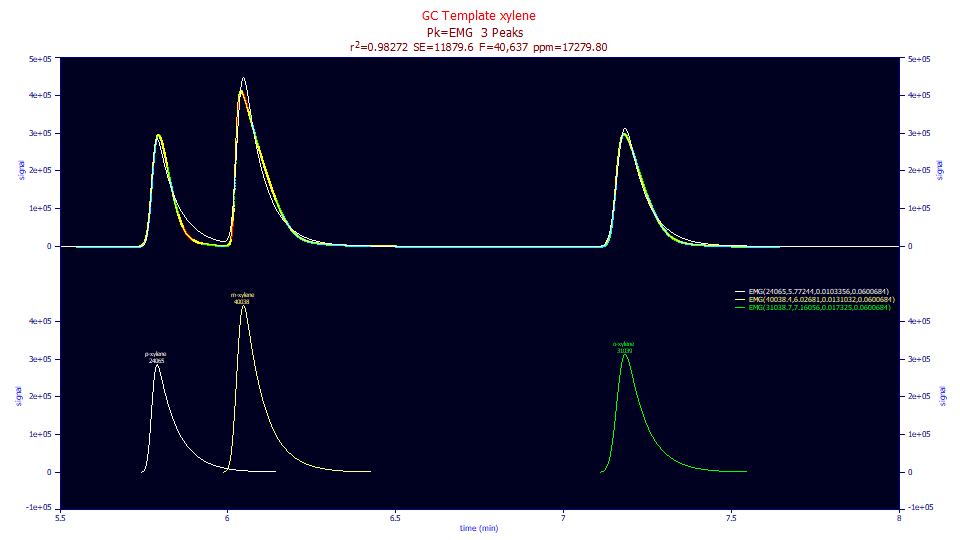
For this data, the EMG fits to 17,280 ppm error when the <e> width is shared across the peaks. These chromatographic peaks, with the system IRFs removed, are strongly non-Gaussian.
The number of models in PeakLab that are capable of reducing to an EMG requires a page's worth of listing. Every model we fit in this topic will reduce to an EMG if the IRF can be reduced to a single component exponential and the core peak to a pure Gaussian. We strongly suggest that you waste no time fitting the EMG separately. If by some chance you actually have an EMG or Gauss<e> peak, these other models will reduce to that shape.
Fitting GC Data using the HVL Model
With no IRF modeling, the HVL fit would also be expected to suffer the error arising from not accommodating the IRF or the nonideality in the ZDD:
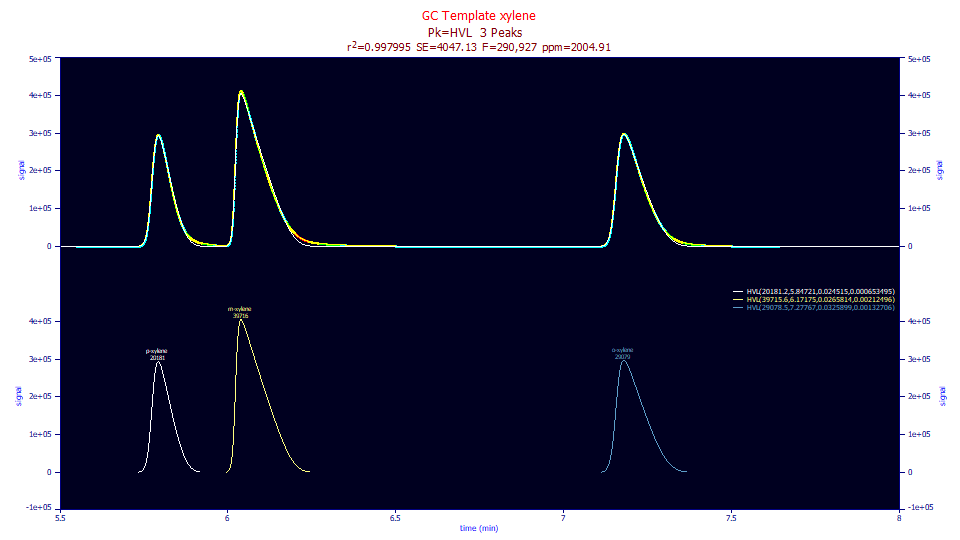
The error in this fit is 2,005 ppm unaccounted variance.
We illustrate the EMG and HVL fits to this data as eluted to illustrate the state of the fitting science as it existed across decades. It is possible that nonlinear modeling of chromatographic peaks never saw the valuation it should have had to a large measure because of that which is shown in these last two fits. For decades, these two models represented the two primary choices offered in nonlinear fitting software. You could have an incomplete IRF with a Gaussian, or an incomplete chromatographic shape with no IRF. Both fits come nowhere near what is realized when accounting both the IRF and ZDD in a complete chromatographic modeling. Contrast these poor EMG and HVL fits with the 30-60 ppm error GenHVL<ge>, GenHVL<e2>, and GenHVL<pe> fits.
Note that the GenHVL and GenNLC models, even with IRFs, will fit to the HVL and NLC shapes if there is no IRF present (something we have never observed) and if there is no ZDD non-ideality (exceptionally rare and probably not real). Further, a generalized HVL will fit both the HVL and NLC shapes. The generalized NLC model will likewise fit both shapes.