PeakLab v2 Documentation Contents R2N Software Home R2N Software Support
Numeric Summary
This option is accessed from the Review's Numeric option. It is used to display all numerical peak analysis information. The Numeric Summary window is live and can remain up while different data sets are selected or deselected in the Review.
The View Numeric Summary for this Fit right click popup menu option opens the Numeric Summary with only the content for the specific fit where this right click popup was invoked. If the window is already open, it is updated with just this specific fit.
This numeric summary can consist of the following items, all selected from the Options menu:
À Fitted Parameters - goodness of fit and fitted parameter values
À Equivalent Parameters - for GenHVL and GenNLC models, the equivalent diffusion-kinetic parameters
À Measured Values - measured peak characteristics; also includes analytic areas if available
À Analytic Moments - the analytic moments of the model
À Deconvolved Moments - the moments of the deconvolutions inherent in a model
À Advanced Area Analysis - additional information in breakdown of components of areas
À Parameter Statistics - peak by peak parameter statistics
À Chromatography Analysis - theoretical plates and resolutions
À Overlap Areas - matrix of overlap areas for all peaks
À Analysis of Variance - ANOVA
À Details of Fit - Convergence State, Iterations, Fit Settings
À Average Multiple Fits - Averages of Coefficients of Variations of multiple similar fits
The Options menu also includes:
À Add Probabilities - adds probability values to the parameter statistics and analysis of variance table
À Add X Area Values - adds the x values at specific cumulative areas for supported models
À 90 %Confidence - uses 90% confidence levels for parameter statistics
À 95 %Confidence - uses 95% confidence levels for parameter statistics
À 99 %Confidence - uses 99% confidence levels for parameter statistics
À Specify Column Dead Time - offers input of dead-time for the specific retentions reported in chromatographic summary if x values were not transformed
The Options menu also includes menu options for selecting a predefined set of options:
À Select All - all sections will be included
À Select Only Fitted Parameters - only the Fitted Parameters section will be included
À Select Chromatography - Fitted Parameters, Equivalent Parameters, Measured Values, Analytical Moments, Deconvolved Moments, Advanced Area Analysis, Chromatography Analysis, Overlap Areas
À Select Statistical - Fitted Parameters, Measured Values, Analytical Moments, Parameter Statistics, ANOVA - Analysis of Variance, Add Probabilities
All elements of this Numeric Summary are computed when the Review is opened with the exception of Overlap Areas. Because this is a matrix of integrations, it can require a considerable time with a large number of peaks or with those that are particularly demanding to compute. Overlap Areas should not be routinely checked unless you really need this information.
The Numeric Summary is toggled on and off by the Numeric button in the Review. The window size and position you choose for the Numeric Summary is automatically saved across sessions. The Numeric Summary uses the PeakLab RTF Viewer to display, modify, and print the information.
Viewing/Averaging only Selected Fits
When multiple data sets are fitted, you can view (and average) only specific fits in the Numeric Summary. The selection process must be done in the Review window. It cannot be done directly within the Numeric Summary window.
Procedure in Review to Select Fits
These instructions apply to the Review window. If you wish to compare/average only certain fits in the Numeric Summary, select those you wish to review by clicking on the specific graph for that fit (the border will turn gray to indicate selection). You can also use the Select this Graph right click menu option for each fit. You can click again on a selected set to deselect it, or use Unselect this Graph from the right click popup menu. When the sets you wish to individually review are selected, select the Plot | Only Selected Fits from the right click menu. Only those data fits will be rendered in the Review graphs, in the Numeric Summary, in the Residuals, in the Explore option, and in the Export.
If you only wish to review one of the fits, you can double click that graph to open a review of just that fit. You can also choose Plot this Fit (or Plot Only this Fit) from the right click menu. When you are finished, and you wish to restore all of the fits, you can once more double click the graph or select Plot All Fits.
Averaging Different Fits without Refitting
If the data sets are identical in peak count, peak model, and in how they were fitted, the Average Multiple Fits will produce useful values for a standard. If you wished run a concentration series for a standard, for example, you can fit all of these data sets in one step and use this selection in the Review to have only those selected sets displayed in the Numeric Summary. The averages and CVs will be automatically updated to reflect those selections. There is no need to create different data files or execute separate fits. Simply select the fits you wish to view and these will be displayed and averaged in the Numeric Summary.
Fitted Parameters
The Fitted Parameters section begins with PeakLab's sum of squares based goodness of fit criteria. These are the r▓ coefficient of determination, a degree of freedom adjusted r▓, the standard error for the fit, the F-statistic for the fit, and the ppm unaccounted variance. The summary then presents each function and its fitted parameter values. If a background was fitted, it is last in the function list.
FittedáParameters
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErráá F-valueáááááá ppmáuVar
0.99991477ááá 0.99991466ááá 0.00968436ááá 9,571,866áááá 85.2295102
áPeakáá Typeáááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá
áááá1áá GenNLCáá 2.01452745áá 3.05122094áá 0.00024861áá -0.0031843áá 1.14665629áá
áááá2áá GenNLCáá 0.57304194áá 4.90636059áá 0.00030115áá -0.0006486áá 1.14665629áá
áááá3áá GenNLCáá 0.66842649áá 5.89144460áá 0.00030732áá -0.0004125áá 1.14665629áá
áááá4áá GenNLCáá 0.30453186áá 9.32507941áá 0.00047594áá 0.00031223áá 1.14665629áá
áááá5áá GenNLCáá 1.06248152áá 21.7583350áá 0.00119313áá 0.01094087áá 1.14665629áá
áááá6áá GenNLCáá 0.60317688áá 27.4861040áá 0.00143410áá 0.00832760áá 1.14665629
The goodness of fit statistics are as follows:
N = count of data observations
np = count of parameters
DOF = degree of freedom, N-np
SSE = sum of squared errors from the fit
SSM = sum of squares about the mean of the dependent variable
MSR = mean square regression
MSE = mean square error
r▓ Coef Det (r▓ Coefficient of Determination)
DF Adj r▓ (Degrees of Freedom Adjusted r▓ Coefficient of Determination)
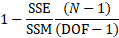
Fit Std Err (Fit Standard Error)
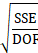
F-value (F-statistic)
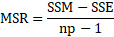
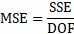
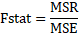
ppm uVar (unaccounted variance, parts per million)
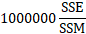
If a peak parameter fails significance, the parameter for that peak will be grayed. This furnishes immediate feedback that a model may be overspecified (that a more complex model has been fitted than the data can support). Bear in mind that significance is a test for a non-zero value. For certain parameters in certain peak models, a failed significance reflects an ideal peak. For example, the a4 asymmetry in the GenHVL model will not be different from zero if the peak is seen by the fitting as close to perfectly symmetric in the third moment of the core density.
Equivalent Parameters
For a GenHVL model, this section converts the parameters from a diffusion-based HVL model to a kinetics-based NLC, furnishing the equivalent parameters had you chosen to make a GenNLC fit. For a GenNLC model, this section converts the parameters from a kinetics-based NLC model to a diffusion-based HVL, furnishing the equivalent parameters had you chosen to make a GenHVL fit.
EquivalentáParameters
áPeakáá Typeáááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá
áááá1áá GenHVLáá 2.01452745áá 3.05122094áá 0.03894996áá -0.0031843áá 0.01463749áá
áááá2áá GenHVLáá 0.57304194áá 4.90636059áá 0.05436082áá -0.0006486áá 0.01270456áá
áááá3áá GenHVLáá 0.66842649áá 5.89144460áá 0.06017585áá -0.0004125áá 0.01171207áá
áááá4áá GenHVLáá 0.30453186áá 9.32507941áá 0.09421421áá 0.00031223áá 0.01158503áá
áááá5áá GenHVLáá 1.06248152áá 21.7583350áá 0.22786153áá 0.01094087áá 0.01200822áá
áááá6áá GenHVLáá 0.60317688áá 27.4861040áá 0.28077663áá 0.00832760áá 0.01171335áá
Measured Values
The initial Measured Values section uses minimization and root-finding algorithms to report amplitude, center (mode or apex), full width at half-maxima (FWHM), asymmetry at half-maxima (Asym50), full width at 10% of maxima (FW Base), and asymmetry at 10% of maxima (Asym10) measured values.
The final Measured Values section first reports an integrated area and its percentages. The integrated area is computed from the minimum X of the fitted data to the maximum X of the fitted data. Note that the integrated area will be less than the analytic area if some portion of that peak is outside this X range of the data. The final four elements are the first, second, third, and fourth moments. The second moment is reported as an SD instead of a variance. The area and moment computations use an automated integration routine which uses a Gaussian Quadrature or Romberg method. Target precision is 1E-8.
MeasuredáValues
áPeakáá Typeáááá áAmplitudeáá ááCenteráááá áááFWHMááááá ááAsym50áááá áFWáBaseáááá ááAsym10áááá
áááá1áá GenNLCáá 17.8716084áá 3.14096487áá 0.10664365áá 0.48899022áá 0.21451372áá 0.42773806áá
áááá2áá GenNLCáá 4.16502418áá 4.92863684áá 0.12935111áá 0.88416960áá 0.25864659áá 0.86456084áá
áááá3áá GenNLCáá 4.41042518áá 5.90649497áá 0.14244138áá 0.93009104áá 0.28489828áá 0.92035906áá
áááá4áá GenNLCáá 1.29103598áá 9.31113024áá 0.22152812áá 1.05741417áá 0.44380373áá 1.08094057áá
áááá5áá GenNLCáá 1.77954450áá 21.3677392áá 0.55844785áá 1.75524682áá 1.14463028áá 2.02141201áá
áááá6áá GenNLCáá 0.84359492áá 27.1673938áá 0.66972658áá 1.45557636áá 1.35828714áá 1.61026579áá
áPeakáá Typeáááá áááAreaááááá áá%áAreaáááá áááMeanááááá ááStdDeváááá áSkewnessááá áKurtosisááá
áááá1áá GenNLCáá 2.01452745áá 38.5467988áá 3.11407765áá 0.04686849áá -0.5508965áá 2.97230910áá
áááá2áá GenNLCáá 0.57304194áá 10.9648208áá 4.92282943áá 0.05490883áá -0.1112859áá 2.99210316áá
áááá3áá GenNLCáá 0.66842649áá 12.7899480áá 5.90283072áá 0.06044843áá -0.0589339áá 2.99493096áá
áááá4áá GenNLCáá 0.30453186áá 5.82703808áá 9.31637063áá 0.09421028áá 0.08095826áá 3.00760983áá
áááá5áá GenNLCáá 1.06248152áá 20.3299594áá 21.4872108áá 0.24940648áá 0.53909101áá 3.10909761áá
áááá6áá GenNLCáá 0.60317687áá 11.5414348áá 27.2649660áá 0.29211223áá 0.40048612áá 3.07535479áá
ááAlláá Totalááá 5.22618613áá 100.000000áá
Analytic Moments
An analytic moment is one which has a closed form solution. PeakLab has closed form analytic moment formulas for many of its peaks functions. Unfortunately, we do not have formulas for the GenHVL and GenNLC families of models. When an analytical moment is not available, the analytic moments will be given for the ZDD (zero-distortion density) of the GenHVL or GenNLC model:
AnalyticáMoments
áPeakáá Typeáááááááá ááFnAreaáááá á%áFnAreaááá ááFnMeanáááá áFnStdDevááá FnSkewnessáá FnKurtosisáá
áááá1áá GenNorm[m]áá 2.01452745áá 38.5467987áá 3.05122094áá 0.03895622áá 0.04391796áá 3.00342915áá
áááá2áá GenNorm[m]áá 0.57304194áá 10.9648208áá 4.90636059áá 0.05436740áá 0.03811728áá 3.00258309áá
áááá3áá GenNorm[m]áá 0.66842649áá 12.7899480áá 5.89144460áá 0.06018204áá 0.03513903áá 3.00219519áá
áááá4áá GenNorm[m]áá 0.30453186áá 5.82703806áá 9.32507941áá 0.09422369áá 0.03475781áá 3.00214782áá
áááá5áá GenNorm[m]áá 1.06248152áá 20.3299594áá 21.7583350áá 0.22788617áá 0.03602769áá 3.00230764áá
áááá6áá GenNorm[m]áá 0.60317688áá 11.5414351áá 27.4861040áá 0.28080552áá 0.03514286áá 3.00219567áá
ááAlláá Totalááááááá 5.22618614áá 100.000000áá
In this case, the moments for the generalized normal with a1=mean, the ZDD, are given. When the Measured Values and Analytic Moments section use the same model, unless some portion of a peak extends beyond the X-range of the data, the analytic and numeric integration areas will be essentially equivalent.
The baseline is not included in this option.
Deconvolved Moments
A given model will have its own specific deconvolutions or simplifications. If an <irf> instrument response function model is fitted, the first deconvolution will be the peak absent this IRF. There will then be a succession of up to two additional deconvolutions. In this example where the IRF was presubtracted and a GenNLC fitted, the moments are for the pure NLC, the peak absent the ZDD adjustments for nonideality, and the Giddings, the peak absent all chromatographic distortion, the expected peak at infinite dilution.
DeconvolvedáMoments
áPeakáá Typeáááááá áááAreaááááá áááMeanááááá ááStdDeváááá áSkewnessááá áKurtosisááá
áááá1áá NLCááááááá 2.01452745áá 3.11359553áá 0.04638333áá -0.5754550áá 3.01434309áá
áááá2áá NLCááááááá 0.57304194áá 4.92280794áá 0.05481415áá -0.1327280áá 2.99963882áá
áááá3áá NLCááááááá 0.66842649áá 5.90282199áá 0.06038679áá -0.0787251áá 2.99874389áá
áááá4áá NLCááááááá 0.30453186áá 9.31636798áá 0.09424530áá 0.06134788áá 3.00315182áá
áááá5áá NLCááááááá 1.06248152áá 21.4859511áá 0.25094228áá 0.51874259áá 3.07620833áá
áááá6áá NLCááááááá 0.60317687áá 27.2643081áá 0.29324707áá 0.38067153áá 3.05177301áá
áPeakáá Typeáááááá áááAreaááááá áááMeanááááá ááStdDeváááá áSkewnessááá áKurtosisááá
áááá1áá Giddingsáá 2.01452745áá 3.05122094áá 0.03894996áá 0.01914805áá 3.00048886áá
áááá2áá Giddingsáá 0.57304194áá 4.90636059áá 0.05436082áá 0.01661949áá 3.00036828áá
áááá3áá Giddingsáá 0.66842649áá 5.89144460áá 0.06017585áá 0.01532116áá 3.00031298áá
áááá4áá Giddingsáá 0.30453186áá 9.32507941áá 0.09421421áá 0.01515497áá 3.00030623áá
áááá5áá Giddingsáá 1.06248152áá 21.7583350áá 0.22786153áá 0.01570857áá 3.00032901áá
áááá6áá Giddingsáá 0.60317685áá 27.4861040áá 0.28077641áá 0.01531470áá 3.00027213áá
These are also numeric integrations similar to those used in the Measured Values section. Again, the integrated area will be less than the analytic area if some portion of that peak is outside this X range of the data, and the second moment is reported as an SD instead of a variance.
Advanced Area Analysis
In most cases, this Advanced Area Analysis section will furnish a measure of the deviation from the non-ideality furnished by the ZDD's higher moment parameters. This is especially useful for higher overload peaks or in instances where you would like to quantify these deviations.
AdvancedáAreaáAnalysis
áPeakáá Typeááááááááááááá Areaáááá áááá%áAreaáááá ááApexAsymááá áNonOverlap1 á%áPkAreaááááááááNonOverlap2 á%áPkAreaáá
áááá1áá GenHVL[Yp2]<e2>áá 323.654533áá 100.000000áá 0.47529501áá 225.535354áá 69.6839781áá 53.8177535áá 16.6281476áá
The Apex Asym furnishes the area asymmetry relative to apex or mode of the peak, the area to the right of the apex divided by the area to the left.
NonOverlap1 is the area of non-overlap between the peak with the ZDD non-ideality and the pure ZDD (the HVL or NLC deconvolved peak). In an overload peak, this is the difference between the peak with the overload shape (minus the IRF) and the deconvolved HVL, the peak that would theoretically exist if there were no overload or any other deviation from this ideality. For analytic peaks, this will be the difference between the GenHVL and HVL, or GenNLC and NLC, and in general, the removal of the ZDD non-idealities will result in only a small amount of non-overlap. In the example below, the non-overlap area is close to 70%. Only 30% of the deconvolved HVL's area is contained in the overload shape.
NonOverlap2 is the area of non-overlap between the peak with and without the IRF removed. In the example below, the area without overlap is 16.6%. One sixth of the overall area of the peak is without overlap between the two peaks.
If the fit is for an experimental two-state model, such as the GenHVL[Z|E], where there are two-components to the ZDD each of which contributes a portion to the overall area of a peak, the state 1 values will consist of the area for the D1 primary component in the (D1|D2) density, where state 2 will the the area for the secondary D2 density, the one adding the anomaly to the overall shape.
For certain models, you will also see a table similar to the following:
áPeakáá Typeáááááááá ááx0.005áááá ááx0.01ááááá ááx0.025áááá ááx0.05ááááá ááx0.25ááááá ááx0.50ááááá
áááá1áá GenHVL_Cáááá 4.46650032áá 4.54866980áá 4.67067048áá 4.77669246áá 5.09764104áá 5.29247708áá
áPeakáá Typeáááááááá ááx0.50ááááá ááx0.75ááááá ááx0.95ááááá ááx0.975áááá ááx0.99ááááá ááx0.995áááá
áááá1áá GenHVL_Cáááá 5.29247708áá 5.44831575áá 5.62480580áá 5.67771494áá 5.73919823áá 5.78142930áá
áPeakáá Typeáááááááá áááxwa50áááá áááxwa90áááá áááxwa95áááá áááxwa98áááá áááxwa99áááá
áááá1áá GenHVL_Cáááá 0.35067472áá 0.84811334áá 1.00704446áá 1.19052843áá 1.31492898áá
áPeakáá Typeáááááááá ááx0.005áááá ááx0.01ááááá ááx0.025áááá ááx0.05ááááá ááx0.25ááááá ááx0.50ááááá
áááá1áá HVL_Cááááááá 4.48743900áá 4.56215809áá 4.67519812áá 4.77555231áá 5.09223273áá 5.29474252áá
áPeakáá Typeáááááááá ááx0.50ááááá ááx0.75ááááá ááx0.95ááááá ááx0.975áááá ááx0.99ááááá ááx0.995áááá
áááá1áá HVL_Cááááááá 5.29474252áá 5.46283811áá 5.66029357áá 5.72103970áá 5.79256978áá 5.84230132áá
áPeakáá Typeáááááááá áááxwa50áááá áááxwa90áááá áááxwa95áááá áááxwa98áááá áááxwa99áááá
áááá1áá HVL_Cááááááá 0.37060538áá 0.88474126áá 1.04584158áá 1.23041170áá 1.3548623
If the model is a GenHVL, or Gen2HVL, the Advanced Area Analysis will evaluate the roots of the GenHVL and HVL cumulatives to get the x values at .5%, 1%, 2.5%, 5%, 25%, 50%, 75%, 95%, 97.5%, 99%, and 99.5% area. If the model is the HVL, only the HVL cumulative is evaluated. The xwa50 through xwa99 values are the peak widths for areas of 50%, 90%, 95%, 98%, and 99%. Note that the xwa50 width will likely be very different from the FWHM (full width at half-maximum, 50% of the peak's amplitude) and the xwa90 width will likely be very different from the FW Base (width at 10% of the peak's amplitude).
If the model is a GenNLC or Gen2NLC, the GenNLC and NLC cumulatives will be evaluated. For the NLC, only the NLC cumulative is evaluated.
The x0.005-x0.995 values will only be shown if the Add X Area Values is checked in the Options menu.
Note that this Advanced Area Analysis only exists for these specific closed form cumulatives. If an <irf> version of one of these models is fitted, you will see these cumulatives absent the IRF, and those will represent the IRF Deconv. and Partial Deconv. deconvolution levels in the Review.
A center of mass is not reported for the model with the <irf> (a peak model that is itself not of a closed-form solution will not a have a closed-form cumulative). You can still manually get this center of mass of the eluted peak with the IRF present by using the Evaluate Fit Model right click menu option in the Review to integrate from a baseline x position prior to the peak to various x positions within the peak, seeking a value where exactly half the reported area is found.
If the peak area is proportional to mass, the mean or first moment of an asymmetric peak will not be the center of mass. You will need to use the x0.50 values from this Advanced Area Analysis for center of mass retention values.
For the GenHVL, Gen2HVL, GenNLC, and Gen2NLC models, a1 is the mean of the ZDD zero distortion density (either a generalized normal or generalized error model). This reflects a concentration independent location of the retention absent the a3 chromatographic distortion (the retention at infinite dilution), but it includes the deviation from theoretical ideality which is present in the ZDD. In the Measured Values section, the Center is the mode or apex of the peak as fitted, and the Mean is the first moment of the actual fitted peak. In the Deconvolved Moments section, the mean or first moment is given for the different deconvolutions.
Parameter Statistics
The Parameter Statistics section is a peak by peak display of parameter statistics, which include each parameter's value, standard error, t-value (parameter value/std error), and confidence limits. The confidence level is set in the Options menu. Note that these standard errors and confidence limits assume normal (Gaussian) errors. If you plan to use these statistics, you should confirm normal errors using a Residuals Graph, inspecting both a distribution and SNP plot.
ParameteráStatistics
Peaká1áGenNLC
áParameterááááá Valueááááááá StdáErrorááá t-valueááááá 95%áConfáLoáá 95%áConfáHiáá P>|t|
áááááááááAreaáá 2.01452745áá 0.00018515áá 10880.4555áá 2.01416454ááá 2.01489036ááá 0.00000
áááááááCenteráá 3.05122094áá 2.9614e-5ááá 1.0303e+5ááá 3.05116290ááá 3.05127899ááá 0.00000
ááááááááWidtháá 0.00024861áá 2.764e-7áááá 899.444774áá 0.00024806ááá 0.00024915ááá 0.00000
áááááDistortnáá -0.0031843áá 1.764e-6áááá -1805.1787áá -0.0031877ááá -0.0031808ááá 0.00000
ááááááNLCasymáá 1.14665629áá 0.01514743áá 75.6997452áá 1.11696604ááá 1.17634653ááá 0.00000
If a peak parameter fails significance, the parameter row for that peak will be grayed. You will be able to see the t-values used to test the significance. For a reasonably-sized chromatographic data set, 90% significance occurs around |t|=1.65, 95% significance occurs around |t|=1.96, and 99% significance occurs around |t|=2.58.
Chromatography Analysis
The Chromatography Analysis section includes the theoretical plates, retention, and resolution. These are described in the Chromatography Notes.
Theoretical Plates
There are four different computations of the theoretical
plate count offered by PeakLab. The Ngauss uses the traditional Gaussian approximation:
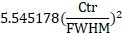
where Ctr is the time location at the center or apex and FWHM is the full width at half-maximum. This
conventional plate count definition assumes a Gaussian peak shape. Although a true Gaussian is seldom
seen in chromatography, by using only a center and FWHM, this plate count is robust insofar as it will
be less impacted by a high asymmetry or by a fattening of the tails. Moment-based methods use all of the
peak information, and can thus be strongly impacted by asymmetry and the fatness of the tails.
The Nmoment, Ndeconv, and Nmodel are based on the first and second central moments.
Unless analytic moments exist for the model, the mean and variance are calculated by numerical integration
of the noise-free parametric model:
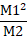
The Nmoment theoretical plate estimate uses the first and second moments from the full fitted model. Everything in the observed peak is accounted, including the IRF distortions.
The Ndeconv estimate is the theoretical plate count for the first deconvolution, as it appears in the separate Deconvolved Moments numeric section. If an IRF-bearing model was fitted, this is the peak with the IRF mathematically removed (peak area is conserved). If a non-IRF closed-form model was fit, and if that model is a once-generalized or twice-generalized HVL or NLC, this first deconvolution in the Deconvolved Moments will be the pure HVL or NLC peak. For IRF-bearing models, the Ndeconv plate count estimates will typically be higher than the Nmoment values since the IRF distortions inflate the second moment. Note that fitting an implicit IRF in a closed-form model, such as the EMG or GMG, results in an Ndeconv for the deconvolved Gaussian.
The Nmodel theoretical plate estimate is based only on the a1 location and a2 width parameters from the model. In the case of a chromatographic model, a1 can be used for M1, the first moment, and a22 can be used for M2, the second moment. For a generalized HVL or NLC chromatographic model, this means the a3 concentration-dependent tailing-fronting and all third and higher moment core density nonidealities (asymmetry and compression/dilation) are removed in addition to the instrumental distortions. Since the Nmodel uses parametric estimates where all nonidealities are separately modeled for both the instrument and the column, this theoretical plate count represents the ideal, the maximum realizable from a separation with no instrumental distortions, and where the chromatographic broadening will be perfectly symmetric. Improvements in formulation and separation which reduce the peak asymmetry, or concentration reductions which lower the chromatographic fronting-tailing, should minimally impact the Nmodel estimate.
For the NLC-based models, the equivalent parameters computations are used to convert the NLC's kinetic width to a statistical standard deviation. The GenHVL and GenNLC models will thus produce equivalent Nmodel values for an identical goodness of fit. For models that are not HVL or NLC based, the full second moment is used, and the IRF, zero-distortion density asymmetry, and concentration-dependent tailing-fronting will be reflected in the Nmodel theoretical plate estimate. If the IRF fits to a significant tailing, the N in this instance may be substantially smaller since those tails can appreciably increase the second moment.
Retention
The retention column contains the thermodynamic retention factor. This will be the a1 value of the fitted peaks. If the x-values were not transformed for dead-time in a transform applied prior to fitting, you can still report the k capacity factor by using the Specify Column Dead Time in the Options menu. The Retention value is adjusted for this dead time. If you have pre-transformed the data for a Retention scale, do not enter a dead time in the Numeric Summary Options menu since the a1 parameter values will already reflect the retention factor values. Also note that this specification of a column dead time in this Numeric Summary only impacts the values reported in the Retention column. An untransformed time-scale fit is in no way altered.
Resolution
The next columns contains the resolution between adjacent peaks. There are two different resolutions reported, the standard FWHM method Res(HW) and a moment-based estimate Res(Stat). The moment-based estimates use the full fitted model of the observed peak.
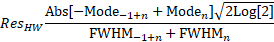
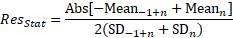
fracNL
The last column contains the fraction to which each peak is in the nonlinear chromatography regime based upon the HVL mathematics. The fraction to which a peak is within the nonlinear chromatographic tailing/fronting is derived directly from the HVL model:
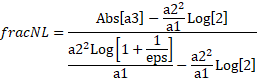
This is based on solving the following term in the denominator of the HVL for 0 and 1-epsilon:
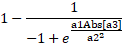
For chromatographic data, which is typically collected to about 4 digits of precision, eps is set to 0.0001. This fracNL value is only reported for HVL, GenHVL, and Gen2HVL models. When this value is below 0, it means the nonlinear regime hasn't yet started and there us still room to increase the concentration for this component and still remain within the linear chromatographic regime. If the value is greater than 1, it means this term in the HVL denominator has essentially reached an asymptote and the model's conservation of mass will change the peak toward a sharp right triangular shape with a significant inflation of the FWHM.
Using the Different Theoretical Plate Values
The two chromatographic analyses that follow are from identical IC separations where the only difference is the concentration of six different analytes.
ChromatographicáAnalysis
áPeakáá Typeáááááááá áNmomentáááá áNdeconváááá áNmodelááááá áNgaussááááá áRetentionáá áRes(HW)áááá áRes(Stat)áá
áááá1áá GenNLC<ge>áá 2504.99051áá 5002.11487áá 5010.51984áá 3921.04482áá 4.47743284áá áááááááááááá áááááááááááá
áááá2áá GenNLC<ge>áá 4739.09980áá 7510.73037áá 7513.74262áá 6163.23332áá 7.48559166áá 8.27738043áá 6.92939876áá
áááá3áá GenNLC<ge>áá 6095.41191áá 9097.81056áá 9103.18638áá 7566.33546áá 9.08821645áá 3.76758884áá 3.33530733áá
áááá4áá GenNLC<ge>áá 7896.33341áá 9491.13108áá 9486.90423áá 8503.76005áá 14.7358867áá 10.2413060áá 9.56236195áá
áááá5áá GenNLC<ge>áá 6749.52129áá 7121.75880áá 7179.73197áá 6792.08965áá 24.3461603áá 10.2413663áá 10.0850580áá
áááá6áá GenNLC<ge>áá 7623.88160áá 7989.53485áá 8075.43786áá 7648.24633áá 27.7222450áá 2.69043687áá 2.68660934áá
ChromatographicáAnalysis
áPeakáá Typeáááááááá áNmomentáááá áNdeconváááá áNmodelááááá áNgaussááááá áRetentionáá áRes(HW)áááá áRes(Stat)áá
áááá1áá GenNLC<ge>áá 729.030401áá 805.845862áá 3868.76802áá 957.420876áá 4.30449113áá áááááááááááá áááááááááááá
áááá2áá GenNLC<ge>áá 3461.82826áá 4392.89691áá 5879.70170áá 4552.73768áá 7.40283975áá 4.54272586áá 4.25769488áá
áááá3áá GenNLC<ge>áá 5210.43069áá 6726.00944áá 7717.76995áá 6550.26389áá 9.02836123áá 3.23714757áá 2.90358801áá
áááá4áá GenNLC<ge>áá 6219.66960áá 6992.48115áá 9172.77375áá 6713.04722áá 14.6654122áá 8.59422124áá 8.19128381áá
áááá5áá GenNLC<ge>áá 2816.17907áá 2864.99435áá 7152.23940áá 3380.17804áá 24.3104437áá 7.38877835áá 6.99143585áá
áááá6áá GenNLC<ge>áá 1613.59862áá 1623.49824áá 6833.08700áá 2028.13802áá 28.1266972áá 1.43592020áá 1.39785980áá
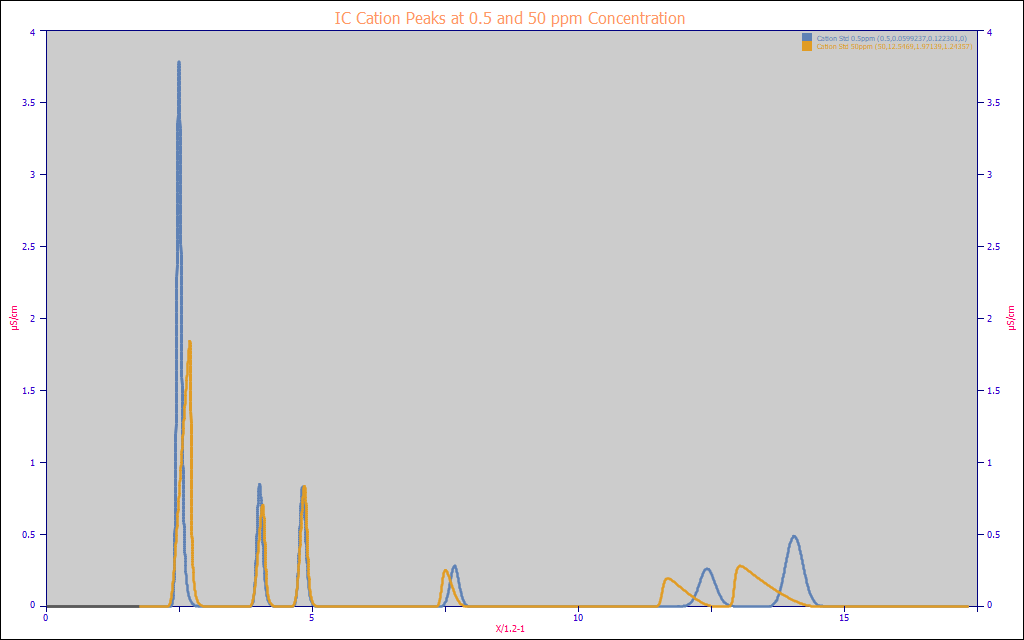
The first table uses 1/10x the normal analyte concentrations and the second table uses 10x the normal concentrations. Area normalized chromatograms for these analyses are in the above plot. The first table reflects very close to Gaussian peaks plus the instrumental distortions, the blue data. The second table reflects peaks with very high a3 tailing and fronting, the amber data. In these data, Peak 1 is a very early eluting narrow width fronted peak and Peak 6 is a very late eluting much wider tailed peak. Peaks 3 and 4 elute at intermediate times with far less fronting or tailing. The IRFs or instrument distortions are close to identical for each of the peaks at both concentrations.
The Ngauss plate count, using only the FWHM for the broadening, is somewhat more robust than the full moment estimates since much of the IRF and tailing-fronting impact the peak well below the half-maximum. Use the Ngauss estimate for conventional comparisons.
The Nmoment, at the low concentrations, reflects the higher impact of the IRF on the narrower first and second peaks. At the high concentrations, the strongly fronted and tailed peaks show a serious loss in estimated efficiency that correlates with the magnitude of tailing or fronting. The second moment is strongly impacted by the IRF and by significant a3 tailing or fronting. Use the Nmoment estimate of theoretical plates for an efficiency that includes instrumental distortions, tailing-fronting from concentration effects, and peak asymmetry arising from nonideality in the media and packing.
The Ndeconv plate count estimates above exclude the fitted IRF. While not quite constant across the six peaks, at the low concentration the Ndeconv estimates are much stabler. At the high concentration, however, the tailing and fronting still produce the same sharp differences with the more linear chromatographic shapes at the low concentration. When you have fitted an IRF, use the Ndeconv estimate of theoretical plates for a measure of the efficiency with the IRF removed.
The Nmodel plate count uses the estimated a2 broadening from the fitted model, removing the chromatographic tailing and fronting reflected in the a3 distortion of a chromatographic model. As you will note, there is now a much better stability across the six peaks irrespective of concentration. Use the Nmodel estimate of theoretical plates as a measure of efficiency with the IRF and the a3 tailing and fronting concentration effects removed. If a generalized model, such as the GenHVL, is fitted, any impact on the efficiency from a higher moment deviation from the Gaussian of the pure HVL or the Giddings of the pure NLC is also removed.
Overlap Areas
The Overlap Areas section consists of a square matrix whose size is the peak count. This option can be quite time consuming with a large number of peaks or with peaks whose functions are computationally demanding. To find the overlap area between any two peaks simply find the desired position in the matrix. The computations use an automated integration routine which uses a Gaussian Quadrature or Romberg method. Target precision is 1E-8.
OverlapáAreas
áPeakáá Typeáááá áPeaká1ááááá áPeaká2ááááá áPeaká3ááááá áPeaká4ááááá áPeaká5ááááá áPeaká6ááááá
áááá1áá GenNLCáá 2.01452745áá 5.1385e-87áá 4.973e-178áá 0.00000000áá 0.00000000áá 0.00000000áá
áááá2áá GenNLCáá 5.1385e-87áá 0.57304194áá 6.3064e-18áá 4.86e-202ááá 0.00000000áá 0.00000000áá
áááá3áá GenNLCáá 4.973e-178áá 6.3064e-18áá 0.66842649áá 1.606e-113áá 0.00000000áá 0.00000000áá
áááá4áá GenNLCáá 0.00000000áá 4.86e-202ááá 1.606e-113áá 0.30453186áá 0.00000000áá 0.00000000áá
áááá5áá GenNLCáá 0.00000000áá 0.00000000áá 0.00000000áá 0.00000000áá 1.06248152áá 1.1842e-29áá
áááá6áá GenNLCáá 0.00000000áá 0.00000000áá 0.00000000áá 0.00000000áá 1.1842e-29áá 0.60317687áá
In the diagonals of the matrix are the actual areas of the peaks.
Analysis of Variance
The Analysis of Variance section includes a standard ANOVA table and also reports the r▓ coefficient of determination, the degree of freedom adjusted r▓, and the standard error for the fit (the square root of the Mean Square Error).
AnalysisáofáVariance
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErr
0.99991477ááá 0.99991466ááá 0.00968436
Sourceááá SumáofáSquaresáááá DFáááááááááá MeanáSquareáááááááá FáStatisticáááááá P>F
Regrááááá 21545.171207352ááá 24áááááááááá 897.71546697301áááá 9571866.1517028áá 0.0000000000
Erroráááá 1.8364409071549ááá 19581ááááááá 9.37868805e-5áá
Totaláááá 21547.007648259ááá 19605
Details of Fit
The Details of Fit section is helpful for subsequently referencing how a fit was made, and its success or failure relative to convergence. Also reported are the number of parameter constraints violated on the final iteration. Many of the items summarize the current Fit Preferences since these can significantly affect the results of any given fit.
DetailsáofáFit
SetáConvergence ááStateááá Iterations áMinimizationá CurvatureáMatrix GAáPrefit GAáConv
áááá1E-6ááááááá Convergedá ááááá10ááá LeastáSquaresá ááááSparse-Roots áááááNone ááá6ááá
Constraint a0ááááá a1ááááá a2ááááá a3ááááá a4ááááá a5ááááá a6ááááá a7ááááá a8ááááá a9ááááá Fail
ááLocalááá 25.00áá 5.00ááá 50.00áá Noneááá Noneááá Noneááá Noneááá Noneááá Noneááá Noneááá áá0
ááGlobaláá Noneááá Noneááá Noneááá Noneááá Noneááá Noneááá Noneááá Noneááá Noneááá Noneááá
Average Multiple Fits
The Average Multiple Fits section is only available where there are multiple fits and those can averaged. All must have exactly the same peak count and use the same model, and there must be no customizations, as in locking a parameter in one fit but not another.
When this option is selected, and averaging is permitted, you will see two separate numeric summaries at the end of summaries for the individual data sets. The first will contain the averages, there will be no data set information, and a title similar to "Average for 12 Fits" will precede a summary where every value is an average of the values from all of the individual summaries. You will need to use caution with respect any value arising from a parameter in one data set that happens to fit to a wild value that severely distorts the average.
The second numeric summary at the end of the individual data set summaries will contain the CV% (coefficient of variation percentages), there will again be no data set information, and a title similar to "CVáPercentáforá12áFits" will precede a summary where every value in that summary is a CV% from the averages of the individual summaries. A CV is simply the SD/mean, here expressed as a percent. You will need to be cautious here since these will be CV percentages whose values will look strange inserted into the same exact Numeric Summary format. When averaging multiple analyses, this format allows you to see all of the variability in one view. It may take some getting used to, but we have found it helpful to see with effortless immediacy which parameters within an average are most tightly determined and which are more variable, and in a % format where everything is comparable.
This averaging can be useful for creating standards. In the example that follows, we took a standard run at three different times with varying columns and column age, and at various concentrations, and fit these in a single step. Using the fit selection described at the beginning of this topic, we automatically averaged the three sets at three different concentrations to see if the variability was lessened at higher sample concentration.
5ppm
Averageáforá3áFits
FittedáParameters
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErráá F-valueáááááá ppmáuVar
0.99999176ááá 0.99999174ááá 0.00361099ááá 50,008,399ááá 8.23618667
áPeakáá Typeáááááááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá ááááááa5áááá ááááááa6áááá ááááááa7áááá
áááá1áá GenNLC<ge>áá 1.77357298áá 2.33640185áá 0.00024239áá -0.0022886áá 1.17011522áá 0.00659790áá 0.04324097áá 0.61185853áá
áááá2áá GenNLC<ge>áá 0.49582206áá 3.79381822áá 0.00027024áá -0.0003633áá 1.17011522áá 0.00659790áá 0.04324097áá 0.61185853áá
áááá3áá GenNLC<ge>áá 0.57367978áá 4.56474247áá 0.00026385áá -0.0001801áá 1.17011522áá 0.00659790áá 0.04324097áá 0.61185853áá
áááá4áá GenNLC<ge>áá 0.25930420áá 7.26517653áá 0.00038954áá 0.00029395áá 1.17011522áá 0.00659790áá 0.04324097áá 0.61185853áá
áááá5áá GenNLC<ge>áá 0.43847415áá 11.9222856áá 0.00081624áá 0.00281495áá 1.17011522áá 0.00659790áá 0.04324097áá 0.61185853áá
áááá6áá GenNLC<ge>áá 0.89753559áá 13.5566498áá 0.00087205áá 0.00617092áá 1.17011522áá 0.00659790áá 0.04324097áá 0.61185853áá
CVáPercentáforá3áFits
FittedáParameters
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErráá F-valueáááááá ppmáuVar
4.5945e-5áááá 4.6074e-5áááá 3.31584855ááá 5.75911264ááá 5.57691676
áPeakáá Typeáááááááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá ááááááa5áááá ááááááa6áááá ááááááa7áááá
áááá1áá GenNLC<ge>áá 0.93704162áá 0.44733312áá 1.61674263áá 0.80244269áá 14.7176342áá 14.9444496áá 1.35253140áá 1.76572075áá
áááá2áá GenNLC<ge>áá 1.10525181áá 0.10674379áá 0.75401308áá 4.10251401áá 14.7176342áá 14.9444496áá 1.35253140áá 1.76572075áá
áááá3áá GenNLC<ge>áá 1.59853985áá 0.14221774áá 0.10465515áá 6.83408844áá 14.7176342áá 14.9444496áá 1.35253140áá 1.76572075áá
áááá4áá GenNLC<ge>áá 1.18375811áá 0.49254277áá 0.39443729áá 7.51451576áá 14.7176342áá 14.9444496áá 1.35253140áá 1.76572075áá
áááá5áá GenNLC<ge>áá 1.00553087áá 0.61434321áá 0.73820553áá 2.05882070áá 14.7176342áá 14.9444496áá 1.35253140áá 1.76572075áá
áááá6áá GenNLC<ge>áá 1.24164589áá 0.77370110áá 0.65903115áá 1.76584386áá 14.7176342áá 14.9444496áá 1.35253140áá 1.76572075áá
10ppm
Averageáforá3áFits
FittedáParameters
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErráá F-valueáááááá ppmáuVar
0.99999203ááá 0.99999201ááá 0.00675034ááá 51,723,654ááá 7.97274523
áPeakáá Typeáááááááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá ááááááa5áááá ááááááa6áááá ááááááa7áááá
áááá1áá GenNLC<ge>áá 3.53790243áá 2.32065496áá 0.00022910áá -0.0044989áá 1.25254712áá 0.00867667áá 0.04331777áá 0.62286980áá
áááá2áá GenNLC<ge>áá 0.98894059áá 3.78785288áá 0.00027418áá -0.0006667áá 1.25254712áá 0.00867667áá 0.04331777áá 0.62286980áá
áááá3áá GenNLC<ge>áá 1.14553797áá 4.56064618áá 0.00026515áá -0.0002762áá 1.25254712áá 0.00867667áá 0.04331777áá 0.62286980áá
áááá4áá GenNLC<ge>áá 0.51944067áá 7.26246876áá 0.00039374áá 0.00083459áá 1.25254712áá 0.00867667áá 0.04331777áá 0.62286980áá
áááá5áá GenNLC<ge>áá 0.87895741áá 11.9127144áá 0.00081961áá 0.00583762áá 1.25254712áá 0.00867667áá 0.04331777áá 0.62286980áá
áááá6áá GenNLC<ge>áá 1.80027348áá 13.5676007áá 0.00089807áá 0.01258912áá 1.25254712áá 0.00867667áá 0.04331777áá 0.62286980áá
CVáPercentáforá3áFits
FittedáParameters
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErráá F-valueáááááá ppmáuVar
5.7016e-5áááá 5.7197e-5áááá 3.14069349ááá 7.03282761ááá 7.15684149
áPeakáá Typeáááááááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá ááááááa5áááá ááááááa6áááá ááááááa7áááá
áááá1áá GenNLC<ge>áá 1.19031673áá 0.40975167áá 0.65897871áá 0.40864655áá 3.91202616áá 5.40931380áá 0.48895763áá 1.56800196áá
áááá2áá GenNLC<ge>áá 1.37221451áá 0.08045825áá 0.77476572áá 2.92067435áá 3.91202616áá 5.40931380áá 0.48895763áá 1.56800196áá
áááá3áá GenNLC<ge>áá 1.55592047áá 0.14689382áá 0.28231932áá 8.19606519áá 3.91202616áá 5.40931380áá 0.48895763áá 1.56800196áá
áááá4áá GenNLC<ge>áá 1.35544799áá 0.52143216áá 0.32934378áá 2.95440225áá 3.91202616áá 5.40931380áá 0.48895763áá 1.56800196áá
áááá5áá GenNLC<ge>áá 1.13461344áá 0.54187712áá 0.44634291áá 1.39547291áá 3.91202616áá 5.40931380áá 0.48895763áá 1.56800196áá
áááá6áá GenNLC<ge>áá 1.18984591áá 0.70939707áá 0.37598270áá 1.49405036áá 3.91202616áá 5.40931380áá 0.48895763áá 1.56800196áá
25ppm
Averageáforá3áFits
FittedáParameters
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErráá F-valueáááááá ppmáuVar
0.99999225ááá 0.99999223ááá 0.01434474ááá 61,756,358ááá 7.74812769
áPeakáá Typeáááááááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá ááááááa5áááá ááááááa6áááá ááááááa7áááá
áááá1áá GenNLC<ge>áá 8.83233211áá 2.29415896áá 0.00025133áá -0.0109638áá 1.15099760áá 0.00881069áá 0.04291114áá 0.62827947áá
áááá2áá GenNLC<ge>áá 2.46684920áá 3.77587739áá 0.00028988áá -0.0017208áá 1.15099760áá 0.00881069áá 0.04291114áá 0.62827947áá
áááá3áá GenNLC<ge>áá 2.86442829áá 4.55441389áá 0.00027141áá -0.0007872áá 1.15099760áá 0.00881069áá 0.04291114áá 0.62827947áá
áááá4áá GenNLC<ge>áá 1.29272307áá 7.26904435áá 0.00039498áá 0.00231398áá 1.15099760áá 0.00881069áá 0.04291114áá 0.62827947áá
áááá5áá GenNLC<ge>áá 2.19303204áá 11.8787540áá 0.00081253áá 0.01410057áá 1.15099760áá 0.00881069áá 0.04291114áá 0.62827947áá
áááá6áá GenNLC<ge>áá 4.48819833áá 13.5868866áá 0.00092725áá 0.03086562áá 1.15099760áá 0.00881069áá 0.04291114áá 0.62827947áá
CVáPercentáforá3áFits
FittedáParameters
r2áCoefáDetáá DFáAdjár2áááá FitáStdáErráá F-valueáááááá ppmáuVar
0.00040330ááá 0.00040432ááá 26.2107987ááá 40.9118570ááá 52.0513290
áPeakáá Typeáááááááá ááááááa0áááá ááááááa1áááá ááááááa2áááá ááááááa3áááá ááááááa4áááá ááááááa5áááá ááááááa6áááá ááááááa7áááá
áááá1áá GenNLC<ge>áá 0.94020389áá 0.47187826áá 2.62482703áá 0.02801510áá 0.63021840áá 4.51584163áá 0.41439057áá 1.10829081áá
áááá2áá GenNLC<ge>áá 0.96980623áá 0.10394166áá 0.84639105áá 1.46689038áá 0.63021840áá 4.51584163áá 0.41439057áá 1.10829081áá
áááá3áá GenNLC<ge>áá 0.88288359áá 0.14607492áá 0.12781207áá 5.09615289áá 0.63021840áá 4.51584163áá 0.41439057áá 1.10829081áá
áááá4áá GenNLC<ge>áá 1.14343169áá 0.49102902áá 0.37273890áá 3.52361828áá 0.63021840áá 4.51584163áá 0.41439057áá 1.10829081áá
áááá5áá GenNLC<ge>áá 0.79244735áá 0.56182612áá 0.54549374áá 1.47090685áá 0.63021840áá 4.51584163áá 0.41439057áá 1.10829081áá
áááá6áá GenNLC<ge>áá 0.82300983áá 0.72613558áá 0.92480419áá 1.54897793áá 0.63021840áá 4.51584163áá 0.41439057áá 1.10829081áá
The advantage of our unusual layout should be more apparent in this example. The test was done at three different concentrations, 5ppm, 10ppm, and 25ppm.
The a0 areas have a slightly better CV% at the higher concentration. The a1 average center values and CV% are little impacted by concentration nor are the averaged a2 time constants. The CV% for a2 looks better at the 10ppm concentration. The a3 distortion is close to linear with concentration. The a3 CV% improve with concentration.
The a4 higher moment ZDD parameter CV% is significantly improved at higher concentration (the greater the strength of the intrinsic chromatographic asymmetry arising from a3, the better a4 is estimated). Here we see that the half-Gaussian component of the IRF, a5, is somewhat impacted by concentration, and it also improves in its CV% with higher sample concentration. The exponential component of the IRF, a6, also becomes less variable with concentration, but here we can see in one quick look that the 'g' component of the <ge> IRF is about 10x more variable than the 'e' component. We can also note that we are computing the shared exponential width in the IRF almost as accurately as the a1 center values of the peaks. The area fraction of the 'g' component of the IRF, a7, is also close to constant in its averages, but the CV improves somewhat with higher concentration. If we look at the goodness of fit averages, there is only the slightest improvement with concentration, and the variability worsens.
While there might be many ways to interpret the information, the improved CV percentages with concentration are clearly apparent. If the a4 higher order ZDD parameter, and the a5 and a6 IRF parameters, were tied to column/instrument health, the reduction in variability in these higher concentration estimates would be important.
Database/Excel Export
The File menu of the Numeric Summary contains the following options for database and CSV (Excel) export:
The Export Fit(s) to CSV or Parquet File... option writes the ASCII CSV file or the Parquet format file that is used for PeakLab's internal databases. It is used for an ASCII export that can be imported into Excel or any independent database.
The Export Fit(s) to &Database... option writes the current fit to the database of your choice. This is the only option that adds the current fit information to a database. You can select any existing PeakLab .duckdb database on your system, or if a name is specified that does not exist, a new database will be created and populated.
The Convert Database to CSV or Parquet... option is a utility function that will convert any PeakLab database to a CSV or Parquet file. This converts the entire contents of the specified duckdb database file to the CSV or parquet file. The parquet file will compressed and much smaller in size. This option allows you to export any of these duckdb databases in a single conversion to either of these portable formats.